相关文档:强化学习方法、Agent RL 与多轮对话
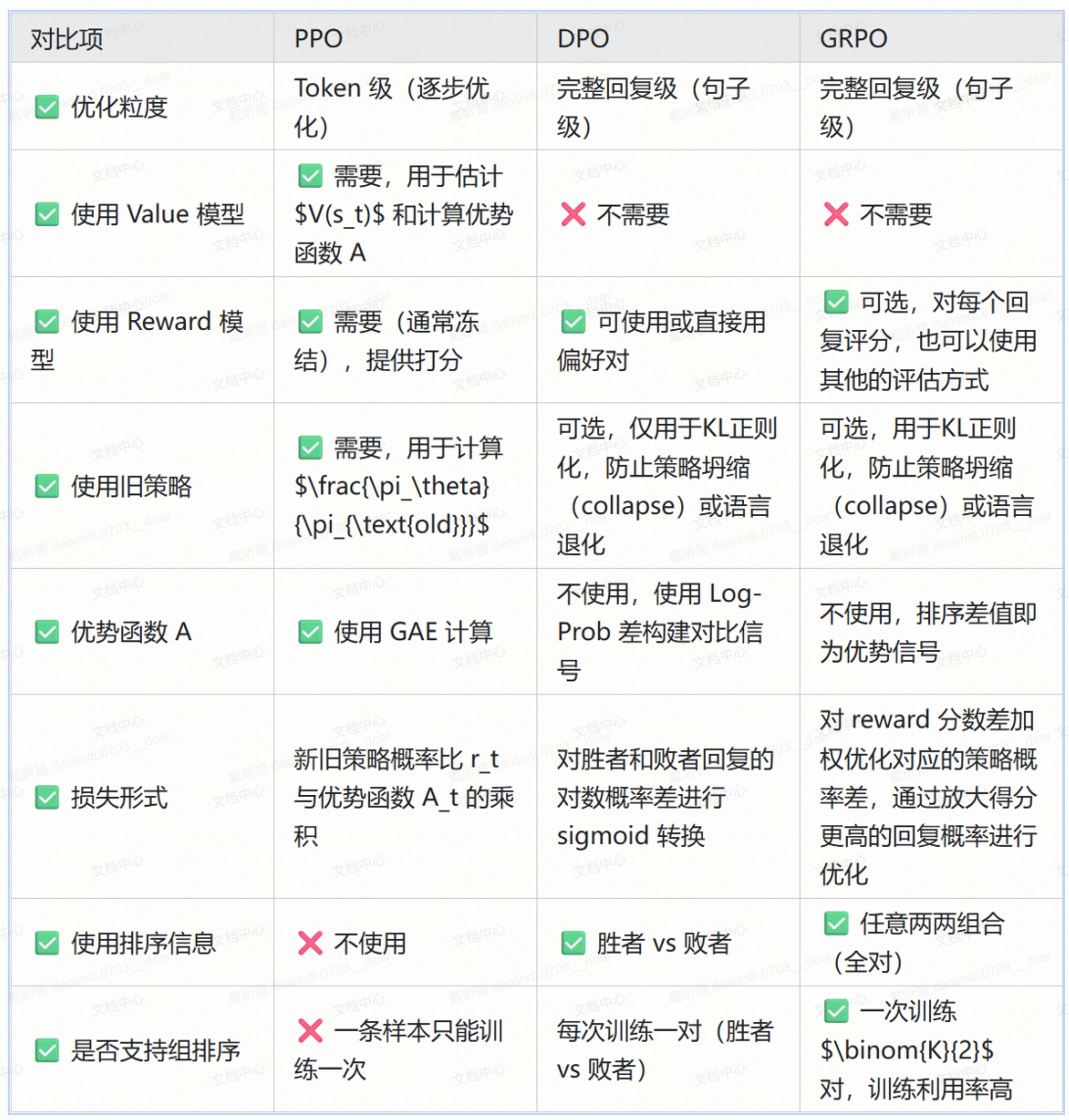
PPO:本质上是 token 级别(逐步)优化。通过 Actor 模型生成回复,Reward 模型提供实际奖励,Value 模型估计每步状态价值并结合 GAE 计算优势函数
DPO:DPO 本质上是基于完整回复的监督式偏好优化,通过 Actor 模型分别计算胜者与败者回复的对数概率差,结合人类偏好对数据构造对比损失,直接最大化胜者相对概率,在无需 Reward 模型和 Value 模型的前提下,实现高效稳定的大模型对齐。主要为了解决PPO训练难度高导致不容易收敛,资源消耗大的问题
DPO缺点
- 容易过拟合:DPO由于缺少reward model的泛化,因此容易直接拟合人类偏好数据,造成过拟合。
- 需求更大标注数据量:相比PPO等,DPO的效果表现更依赖标注数据量。
- 多任务适配较难:由于DPO仅依赖数据,所以如果需要进行多任务的对比,则需要从头标注涉及到多个维度的数据,但是在线策略的方法可以通过单个维度的数据,训练不同的多个reward model,引入多维度的奖励。
为了在PPO和DPO之间取得平衡,deepseek提出了GRPO(群组相对优化策略),在一定程度上能够通过去掉价值模型Value Model,缓解PPO对于显存的瓶颈,确保策略更新的稳定性和高效性;同时保留了Reward Model,避免了DPO因为直接拟合人类偏好数据,而容易造成的过拟合和效果不佳。
其中GRPO跟PPO的重要区别,主要是==去掉了Value Model==,同时使用Policy Model的多个output采样的Reward Model输出的多个奖励的平均值作为优势函数。
GRPO:GRPO 本质上是基于完整回复的相对偏好强化学习优化,针对每个 prompt,Actor 生成多个候选回复,Reward 模型给出评分后构造所有有序偏好对;每对通过计算回复间的 log-prob 差构建对比损失,并用评分差(即优势)作为权重,最大化胜者概率相对劣者的提升幅度,从而在无需 Value 模型的情况下,用多对相对优势信号优化 Actor 策略,实现高效、轻量的大模型偏好对齐。
GAPO:GAPO 本质上也是基于完整回复的强化学习方案。Actor 生成回复,判别器作为奖励模型评估输出是否满足预设约束,通过构造合规与不合规的对比样本,最大化生成回复获得高判别分数的概率,同时反向优化判别器区分真实与虚假,从而在无需显式偏好对和 Value 模型的前提下,以对抗博弈方式优化 Actor,实现细粒度可控的大模型对齐。