强化学习方法
相关文档:[RL 算法对比](./Tech—RL 算法对比.md)、Agent RL 与多轮对话、回复模型强化学习
概述
见 link
强化学习的两个实体:智能体(Agent)与环境(Environment)
强化学习中两个实体的交互:
- 状态空间****S:S即为State,指环境中所有可能状态的集合
- 动作空间A:A即为Action,指智能体所有可能动作的集合
- 奖励R: R即为Reward,指智能体在环境的某一状态下所获得的奖励。
Loss的直观设计
表示基于当前状态(前缀Tokens)输出下一个Token(A_t)的prob,V_t代表奖励
- 当 Vt>0 时,意味着Critic对Actor当前采取的动作给了正向反馈,因此就需要在训练迭代中提高
,这样就能达到减小loss的作用。 - 当 Vt<0 时,意味着Critic对Actor当前采取的动作给了负向反馈,因此就需要在训练迭代中降低 P(At|St) ,这样就能到达到减小loss的作用。
引入优势(Advantage)
对NLP任务来说,如果Critic对 At 的总收益预测为 Vt ,但实际执行 At 后的总收益是 Rt+γ∗Vt+1 ,我们就定义优势为:
Adv衡量的是我们执行At后,也就是生成新的token之后的收益值
PPO
REINFORCE Leave-One-Out
- 留一法**(Leave-One-Out)** 构造基线,即第 个样本的基线为除自己外的其他 个样本的均值
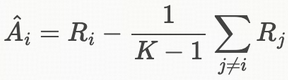
**KL-in-loss → KL-in-reward:同一个 log‑prob 的梯度同时对 task reward 和 KL 做平衡,而不是拆成两部分 loss 再相加。
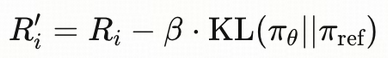
REINFORCE++
- Global Advantage Normalization(GAN): 分母用Batch STD Advantage,adv 分布更稳定,训练曲线更平滑

- 与DAPO相同的token-level loss,与RLOO相同的KL-in-reward 等,全局归一化更好,scale震荡的鲁棒性更好
Reinfoce++存在的缺点:会引入偏置,不同的prompt可能天然reward就会更高一些,reward更高的prompt任务会主导更新,所以Rinforce++更适合相似、相同评判标准的任务,不适合跨域、多任务混合训练。
GSPO
GSPO对MOE模型的改进点,MOE的强化无脑GSPO
- MOE模型GRPO痛点:同一条 rollout 样本,在做了一次或几次梯度更新后,新旧策略下激活的专家集合会明显变化;GRPO 用的是 token-level importance ratio
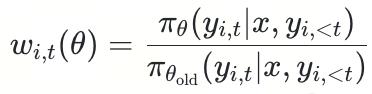 但在 MoE 里,
但在 MoE 里,
- 改进
GSPO(Group Sequence Policy Optimization)对 MoE(Mixture-of-Experts)模型最“特别”的优化点,核心不是改路由器结构本身,而是把 RL 的 off-policy 校正与裁剪(clipping)从 token 级切换到序列级(sequence-level),从而天然规避 MoE 的“路由/专家激活波动”对训练稳定性的破坏,并彻底消除对 Routing Replay 这类 MoE 专用补丁的依赖。
Sequence-Level
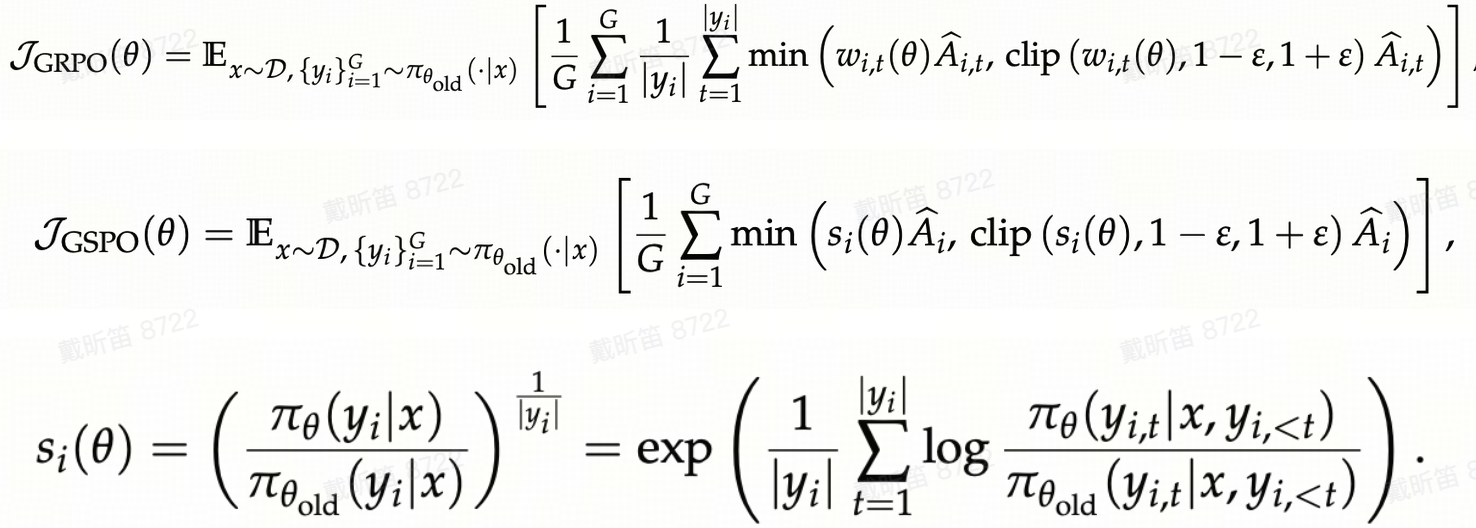
GRPO公式序列化得到GSPO的公式,Adv本质上跟token无关,仅仅是将w的token-level weight聚合成sequence-level的s,而s本质也是通过token-level的分布差聚合而成。
Sequence-level 的IS weights相对于token-level更加平滑,避免了极端token的影响(相比于token-level的clip,sequence-level clip明显更易充分学习),稳定性更好。
Token-Level
这个方法结合了sequence_level和token_level,融合了两者的重要性

为什么GSPO更加平滑
原理类似于
的方差为
,求和之后方差更小,自然更平滑
强化学习问题引入及解决方案
🐞 Reward Hacking解决方案
- 从reward本身下手,优化reward设计,或者使用multi_reward
- 过程信号,矫正过程错误。我们的answer应该算是只有过程?没有明确的答案
- 可疑高分样本采样标注
- 守门人LLM judge(safeguard / critic)
- KL散度加权
📊 RLHF指标
pg_loss(policy gradient loss)
“策略更新的主要项”。在 PPO/GRPO 里常形如:
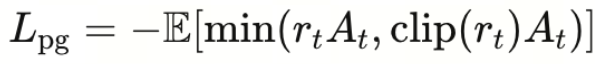
pg_loss趋势与Adv相似,由于Adv是归一化、中心化的,所以pg_loss与Adv同样,是在某个值(0)附近波动;GRPO的更新目标在于
,所以loss恒定不影响更新
pg_clipfrac(policy gradient clip fraction)
统计有多少比例的样本 触发了 clipping
怎么看
- 太高:说明大部分样本都被裁剪,更新被严重限制(学不动或效率低)。
- 太低:说明几乎没触发裁剪,更新温和;但如果同时 KL 很高,说明不是温和,是 ratio 在别的地方失控或实现统计口径不同。
Grad norm
是什么
- 当前 step 的梯度大小(通常是全参数 L2 norm,可能是裁剪前或裁剪后,取决于日志点)。
- 它是训练稳定性的“地震仪”。
怎么看
- 重点看:是否频繁尖峰、是否持续变大、是否突然接近 0。
常见态势
- 正常情况下会抖动,但分布相对稳定;偶尔 spike 可以接受,关键是是否伴随 loss/KL 的异常。
异常信号
- grad_norm 经常爆到很大:学习率过高、advantage/奖励尺度过大、batch 太小噪声大、混精溢出风险。
- grad_norm 长期很小:学习率太低、clip/β 太强、梯度被裁剪得太狠、或者模型已进入平台期。
entropy(熵)
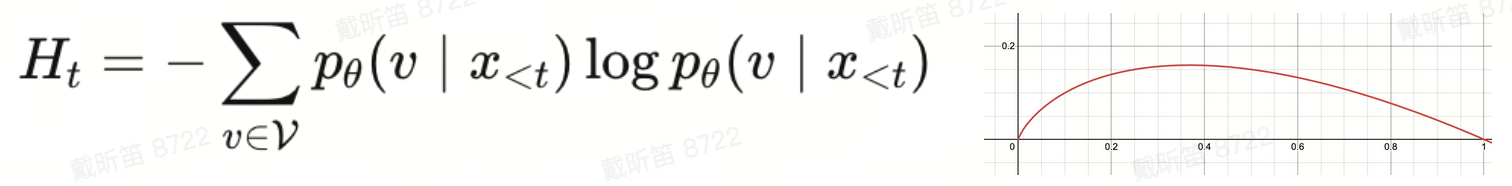
GRPO、PPO中⬇️:
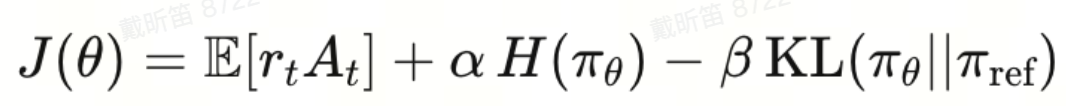
是什么
- 输出 token 分布的不确定性(随机性)。高=更分散、更探索;低=更确定、更“模板化”。
- 常作为正则项:鼓励探索、避免策略过早塌缩。
怎么看
- 看趋势:缓慢下降常见;断崖式下降危险(塌缩/骗分/更新过猛)。
- 也要结合质量指标:entropy 降低但 reward 提升且 KL 可控,通常 OK。
异常信号
- entropy 暴跌 + KL 上升 + grad_norm 尖峰:更新过猛,策略可能“锁死”到某种模式。
- entropy 很高但 reward 不涨:探索多但没学到;可能奖励信号弱/噪声大/优势估计不稳定。
训练算法选择
mid-training、rlhf冷启、知识学习 等阶段使用SFT
端到端偏好学习、风格对齐、边界判定能力缺失时用DPO
RLHF适用比较广,只要reward能准确表达偏好的样本均能适用,在逻辑推理、风格偏好、指令遵循、回复准确性等各个维度可以采用各种不同的function/model去进行强化。
SFT
优化response风格、token级别预测、学会以xx样的风格进行回复,使模型的回复接近人类,并且形初步的推理能力。
优点是:简单稳定、能够学到基本能力、迅速掌握综合能力和风格。
缺点是:无重要性区分,无sequence-level级别判定,因此推理逻辑能力欠缺,无法识别样本间token或phrase之间的偏好。
DPO
SFT仅仅包含正样本,等同于对所有other tokens做偏离,对于0分、1分、2分的token甚至未被选中的3分token是一视同仁的。而事实上,根据token之间的同一性和对立性,显然这样的学习是不充分的。DPO通过引入负样本,扩大正负样本prob之间差值,从而达到显著偏理 负tokens同时显著靠近正tokens的目的。
优点是:实现简单,无需额外的reward_model,仅仅从pair中学到风格偏好,直接降低模型对于偏见、歧视、敏感言论等回复的透发率;对于缺失先验边界判定能力的任务,往往更加适用。
缺点是:不稳定,原生DPO模型回复漂移严重;难以做细粒度拆解,难以学到难pair样本中隐含的偏好信息;适用场景比较受限。
RLHF
RLHF是对response自身做优势计算、分数判定,从而敲定这次response是否是一个理想的结果,本质上也是要偏离低分样本并拟合高分样本,但并非如DPO是提前设定高低分response,而是采样在线reward计算来进行判定,相较于DPO来说,RLHF对于高低分的判定是更加灵活、精细的。
优点是:无监督、优化更加精细,能够支持在逻辑推理能力的优化,上限高,灵活,适用场景多样
缺点是:需要一套鲁棒的判定方法、即reward function/model,否则容易触发reward hacking等问题,而这个reward model/function制定/训练成本会很高。
强化学习算法
PPO、GRPO、GSPO、DAPO、RLOO、Reinforce++等
除了PPO以外均是基于Group的算法,但Adv计算的计算各有不同
以GRPO为baseline⬇️
- DAPO更适用于推理强化,其Loss决定了它的长response权重更大,那么长response的优劣势均会被进一步放大
- GSPO更加适用于MOE稀疏专家网络训练,稳定性更强,但实际验证下发现其收敛速度会更慢,但理论上收敛后的reward会更高。
- Reinforce++的Adv是针对整个batch的Adv,此类算法应当更适用于统一reward标准的任务,例如ground_truth相似度,答案计算准确度等。
多轮改写应用的GRPO + Dynamic Sample(from DAPO),回复强化应用的GRPO + GSPO。
GRPO in 多轮改写
多轮改写本应是一个不存在的任务,我们本可以直接根据多轮信号输出Planning;但一方面是由于迭代难度优化、一方面是基于懂车帝场景的需求相关性优化,我们设计了这个Task,希望能够提炼出用户的精准需求。本质上是一个基于memory进行信息精炼的过程,只不过该业务场景下只包含单个session的history作为短期记忆的信号。
reward设计
针对BAD结果设计边界明确的规则,降低训练难度和不稳定性。
对于Query需求精炼这一点,其评判标准与搜索、BOT回复相同,存在 BAD→GOOD→BETTER 这样的执行标准,其中BAD可以精准识别出现,但是GOOD和BETTER之间并没有明显的区分界限,因此在多轮改写中的reward设计仅通过Agent划分出多个BAD标准,而我们强化的目标便是远离这些BAD reply。
训练过程中没有遇到reward hacking问题,应当是当时reward设计本身就是比较完备的