面试题八股
后续组织规则
- 一级标题只放知识域,不放单个零散概念。当前按
训练基础 -> 训练工程与显存优化 -> Transformer / LLM 架构 -> 强化学习 -> RAG组织,后面尽量沿着这条主线扩。- 二级标题放可以独立成一道面试题的主题,比如
BatchNorm、MHA、GAE 与 PPO Loss。- 三级标题放固定槽位,比如“公式 / 直觉 / 优缺点 / 手撕 / 工程判断”,不要为了一个补充点单开一级标题。
- 新增内容时,先判断它是在讲训练稳定性、模型结构、训练范式还是应用系统,再决定挂在哪个一级标题下。
- 只有当某个方向会连续新增 3 个以上独立主题时,再考虑新开一级标题,否则优先并入已有大类。
1 归一化与训练稳定性
1.1 Batch Normalization(BN)
1.1.1 ICS:协变量偏移
Covariate Shift(协变量偏移) 是指训练集和测试集输入分布不一致,导致模型泛化能力差。
作者将这个概念推广到了神经网络内部,提出了 Internal Covariate Shift (ICS):
在深度网络中,激活函数会改变各层数据的分布。随着网络层数加深,这种分布的变化会被不断累积和放大。 也就是说 ICS 指的是层与层之间数据分布的不稳定
1.1.2 饱和激活函数梯度消失
饱和激活函数(如 Sigmoid 和 Tanh):当数据分布发生偏移时,很多神经元的输出会落入激活函数的 饱和区。
1.1.3 BN:解决梯度消失
- 将每层输入按照特征channel拉回均值 0、方差 1 的标准分布
- 然后,加入缩放和平移变量 γ 和 β:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。 这两个参数是可学习的参数。
1.1.4 作用
- 允许较大 lr
- 减弱对初始化的依赖性
- 让数值更稳定
- 轻微正则化作用(相当于加 noise,类似 Dropout)
1.1.5 bs 太大/太小会怎样
- 太大
- OOM
- 需要跑更多 epoch(更新次数减少,为了达到同样的精度,大 Batch 通常需要跑更多的轮次(Epoch)或者配合更大的学习率,甚至有时最终泛化效果还不如小 Batch。)
- 直接固定了梯度方向(趋向于全量数据了),很难更新,会直接落入局部最优/鞍点
- 小 bs 带有一定随机噪声,有几率从局部最优跳出
- 太小
- 算出来的均值和方差具有随机性,不能反映真实分布
不方便用大 bs 咋办
- LN
- Group Norm(把 channel 分组,组内求 mean、std)
1.2 Layer Normalization(LN)
1.2.1 公式
和 BN 一样的公式,不过是在 seq 维度进行。
1.2.2 手撕
import torch
import torch.nn as nn
class MyLayerNorm(nn.Module):
def __init__(self, hidden_dim, eps=1e-5):
super().__init__()
# gamma 和 beta 是每个特征维度一个,初始化为 1 和 0
self.gamma = nn.Parameter(torch.ones(hidden_dim))
self.beta = nn.Parameter(torch.zeros(hidden_dim))
self.eps = eps
def forward(self, x):
# x shape: [Batch, Seq_len, Hidden_dim]
# 在最后一个维度计算均值和方差
mean = x.mean(dim=-1, keepdim=True)
# unbiased=False 表示使用总体方差(分母为 N),这是标准做法
var = x.var(dim=-1, keepdim=True, unbiased=False)
# 归一化并线性变换
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out
def test_ln():
b = 2
s = 4
h = 8
x = torch.randn(b,s,h)
ln = MyLayerNorm(h)
output = MyLayerNorm(x)
print(x.shape)
print(output.shape)
if __name__=="__main__":
test_ln()
class DxdLayerNorm(nn.Module):
def __init__(self,hidden_dim,eps = 1e-5):
super.__init__()
self.gamma = nn.Parameter(torch.ones(hidden_dim))
self.beta =
self.eps = eps
def forward(self,x):
mean = x.mean(dim = -1,keepdim = True)
var = x.var(dim = -1,keepdim = True)
out = (x-mean)/torch.sqrt(var+self.eps)
out = out*self.gamma+self.beta
return out1.3 RMSNorm
1.3.1 公式
与layerNorm相比,RMS Norm的主要区别在于去掉了减去均值的部分
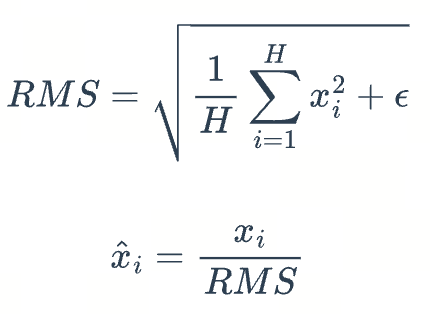
1.3.2 好处
- 不用减均值,效率提升
- 实现了与 LayerNorm 相当的性能
- 减少了对均值的依赖,适用于不同的输入分布
1.3.3 手撕
import torch
import torch.nn as nn
class DXDRMSNorm(nn.module):
def __init__(self,hidden_dim,eps = 1e-5):
super.__init__()
self.gamma = nn.Parameter(torch.ones(hidden_dim))
self.eps = eps
def forward(self,x):
RMS = torch.sqrt(torch.mean(x.pow(2),dim = -1,keepdim = True)+eps)
output = x/RMS
output = output*self.gamma
return output
def testRMS():
b = 4
s = 8
h = 2
x = torch.randn(b,s,h)
rms_norm = DXDRMSNorm(h)
output = DXDRMSNorm(x)
print(x.shape)
print(output.shape)
print("params:",list(rms_norm.parameters()))
if __name__ == "__main__":
testRMS() 2 常见损失函数
2.1 MSE
2.1.1 公式
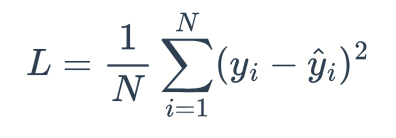
2.1.2 手撕
def mse(y_true,y_pred):
sqared_err = (y_true-y_pred)**2
return np.mean(squared_err)
y_true = np.array([2.0,4.0,5.0])
y_pred = np.array([3.0,4.4,5.5])
print(mse(y_true,y_pred))
2.2 CE(交叉熵)
2.2.1 公式
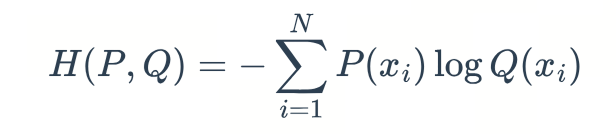
2.2.2 手撕
import numpy as np
def ce(y_true_onehot,y_pred):#in: s*v
#softmax
exps = np.exp(y_pred-np.max(y_pred,axis = 1,keepdims = True))
softmax_out = exps/np.sum(exps,axis = 1,keepdims = True)
eps = 1e-7
clipped = np.clip(softmax_out,eps,1-eps)
ce= -np.sum(y_true_onehot*np.log(clipped),axis = 1)
return ce
y_pred = np.array([[10, 2, 1], [1, 5, 2]], dtype=float)
y_true_onehot = np.array([[1, 0, 0], [0, 1, 0]])
print(ce(y_pred, y_true_onehot))
3 训练工程与显存优化
3.1 梯度累积、梯度检查点、激活检查点
3.1.1 区分
- 梯度累积(gradient accumulation):改的是一次参数更新前要吞掉多少个
micro-batch,本质上是在模拟更大的 batch。 - 激活检查点(activation checkpointing):改的是前向过程中保存多少中间激活,反向时是否允许重算。
- 梯度检查点(gradient checkpointing):在大多数深度学习语境里,基本就是激活检查点的另一个叫法。
这样理解:
gradient accumulation= 攒梯度,模拟大 batchgradient checkpointing/activation checkpointing= 少存激活,反向重算
3.1.2 梯度累积
梯度累积说白了就是:把大 batch 拆成多个 micro-batch,每次都反传,但不每次都更新参数。
正常训练的一步很直接:取一个 batch,前向算 loss,反向得到梯度,optimizer.step() 更新参数,再 optimizer.zero_grad() 清梯度。
梯度累积改动的只有一件事:把一个大 batch 拆成多个小的 micro-batch。每个小 batch 都做 forward + backward,但先不更新参数,而是把梯度攒起来,攒够若干步再统一 step。它解决的就是“显存装不下大 batch,但我还想保留大 batch 梯度更稳的性质”。
例如目标等效 batch size 是 128,但单卡一次只能放 32,那么就可以设置:
micro-batch size = 32gradient accumulation steps = 4effective batch size = 32 x 4 = 128
只要 loss 的缩放方式处理对了,梯度累积在数学上就是在近似大 batch 训练。
如果大 batch 的 loss 定义成平均值:
那么它的梯度就是:
所以工程上通常会把每个 micro-batch 的 loss 先除以 acc_steps,然后逐次 backward(),这样累积出来的梯度就和大 batch 直接反传近似等价。
它主要省的是单次前向/反向的激活显存。参数、梯度、优化器状态并不会因为梯度累积本身而大幅减少。真正被压下去的是单次 micro-batch 对应的 activation memory。
代价也很直接:
- 同样一轮样本要做更多次
forward/backward,训练更慢 - 参数更新频率降低,训练动力学会变化
- 碰到 BatchNorm 时,大 batch 和多个 micro-batch 不再严格等价,因为统计量不是同一份
- 学习率调度、日志 step、梯度裁剪、
optimizer.step()的触发时机都要跟着 accumulation step 对齐
optimizer.zero_grad()
for step, batch in enumerate(dataloader):
loss = model(batch)
loss = loss / acc_steps
loss.backward()
if (step + 1) % acc_steps == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
optimizer.zero_grad()3.1.3 为什么 micro-batch mean 不等于 global token mean
这个坑在 LLM 训练里非常常见。最短的记法其实就两句:
global mean:每个 token 一票mean(mean(...)):每个micro-batch一票
只要各个 micro-batch 的有效 token 数不同,这两者就不等价。这里不是精度误差,问题出在统计口径变了。
最核心的区别就是:
- 先分组求平均,再对组平均
- 和
- 把所有样本放一起求一次总平均
只有在每组大小完全一样时才相等。
先看一个最简单的数值例子。假设两组数分别是:
- 第一组:
[1, 3] - 第二组:
[100, 100, 100, 100] - 先每组求均值,再对两组求均值:
第一组均值 = (1 + 3) / 2 = 2
第二组均值 = (100 + 100 + 100 + 100) / 4 = 100
再平均 = (2 + 100) / 2 = 51- 把所有数直接放在一起求一次总均值:
总均值 = (1 + 3 + 100 + 100 + 100 + 100) / 6
= 404 / 6
≈ 67.33两者不一样,因为:
Tip
- 前一种做法是按组等权
- 后一种做法是按元素等权
映射到 LLM 训练里,每个 token 都有 loss,但每个 micro-batch 里真正参与训练的有效 token 数往往不同。
常见原因有这些:
- padding token 会被 mask 掉
- prompt token 可能不计入监督
- 不同样本长度不同
- 只训练 answer 部分
- packing 后每个
micro-batch的有效 token 数也可能不同
设第 i 个 micro-batch:
- 有效 token 数是
n_i - 这些 token 的 loss 总和是
S_i - 这个
micro-batch的平均 loss 是L_i = S_i / n_i
真正的 global token mean 应该写成:
等价地,也可以写成:
这本质上是按 token 数加权平均。
而很多人顺手写出来的其实是:
这本质上是按 micro-batch 等权平均。
只有所有 micro-batch 的有效 token 数完全一样时,这两者才会相等:
再看一个更贴近训练的例子。假设 grad_acc = 2。
第一个 micro-batch:
n_1 = 2- token loss 是
[1, 1] - 所以
L_1 = 1
第二个 micro-batch:
n_2 = 8- token loss 是
[3, 3, 3, 3, 3, 3, 3, 3] - 所以
L_2 = 3
如果先对每个 micro-batch 求 mean,再平均:
L_naive = (1 + 3) / 2 = 2如果对 global batch 的所有 token 直接求 mean:
S_total = 2 * 1 + 8 * 3 = 26
n_total = 2 + 8 = 10
L_global = 26 / 10 = 2.6差很多,原因也不神秘:
L_naive认为两个micro-batch一样重要L_global认为每个 token 一样重要
训练目标通常应该是后者。
更重要的是,这不只是 loss 记录值不同,反向传播出来的梯度权重也会变。
如果 batch 内先取 mean,再对 K 个 micro-batch 平均:
而真正的 global token mean 对应的梯度应该是:
区别在于:
- 前者是每个
micro-batch先除自己的n_i - 后者是所有 token 梯度先加起来,再统一除总 token 数
所以当 n_i 不同时:
- 小
micro-batch会被放大权重 - 大
micro-batch会被缩小权重
这和“每个 token 同权”的目标是冲突的。
这个问题和数值精度几乎没关系。不是 fp16、bf16、fp32 带来的舍入问题。哪怕用无限精度实数去算,这两个目标函数也还是不一样,因为一个是加权平均,一个是等权平均。
下面这种写法很容易在不知不觉中把目标换成 micro-batch 等权平均:
loss = F.cross_entropy(logits, labels, ignore_index=-100, reduction="mean")
loss = loss / grad_acc_steps
loss.backward()它实际做了两件事:
- 每个
micro-batch内部先按有效 token 求 mean - 再在梯度累积的意义上,对这些
micro-batch等权混合
更合理的做法是不要直接累计各 micro-batch 的 mean loss,而是累计:
- 每个
micro-batch的loss_sum - 每个
micro-batch的valid_token_count
最后再按总 token 数归一化,也就是:
从本质上保证“每个 token 同权”。
3.1.4 激活检查点
标准反向传播会在前向阶段保存大量中间激活,因为反向算梯度时需要它们。模型一深、序列一长,这部分显存往往比直觉里更贵,Transformer 尤其明显。
激活检查点的想法很朴素:前向时不保存所有中间激活,只在少数位置保存“检查点”;等到反向时,如果某一段缺失中间激活,就从最近的检查点开始,把那一小段前向再重跑一遍,把需要的激活临时算出来,再继续反向。
假设一条计算链是:
x -> layer1 -> layer2 -> layer3 -> layer4 -> y标准训练会保存 layer1/2/3/4 的激活。激活检查点可能只保留 x、layer2、layer4。等反向传播走到 layer3,如果发现缺激活,就从 layer2 再跑一次到 layer3。
这件事的本质就是:
- 用额外计算换更低显存
它省的是中间激活显存,不是参数、梯度或优化器状态。模型越深、seq_len 越长、hidden size 越大,这个技巧越值钱。
代价也很明确:
- 训练更慢,因为反向期间要重算前向
- 切分粒度不合适时,重算开销会偏大
- 调试更复杂,某些带随机性的算子要注意可重入和随机数状态
很多工程经验里,activation checkpointing 会带来大约 20% 到 50% 甚至更高的额外计算开销,具体取决于 checkpoint 切分方式。
from torch.utils.checkpoint import checkpoint
def block(x):
x = layer1(x)
x = layer2(x)
x = layer3(x)
return x
x = checkpoint(block, x)这段代码的含义不是“保存梯度”,而是:前向跑 block(x) 时不保留完整中间激活,等反向需要时再把 block 重跑一遍。
3.1.5 梯度检查点
很多中文资料里把 gradient checkpointing 译成“梯度检查点”,这个名字本身有点误导,因为它听起来像是在保存梯度,甚至像在做梯度校验。实际上它主要处理的是 activation memory,不是把梯度单独存成某种 checkpoint。
所以在主流工程语境下:
- 梯度检查点 ≈ 激活检查点
英文之所以叫 gradient checkpointing,是因为它服务的对象是梯度计算过程。反向传播要算 gradient,而计算 gradient 又依赖前向激活;checkpointing 的作用,是让这个 gradient computation 不需要保留全部激活。名字落在 gradient 上,但真正被省掉和重算的对象主要是 activation。
3.1.6 不要和 gradient checking 混淆
还有一个很容易看串的词是 梯度检查(gradient checking)。这和上面的 checkpointing 完全不是一回事。
gradient checking 是调试方法,用数值差分去验证自动求导算出来的梯度对不对,例如:
它是在验梯度的正确性,不是在省显存。
所以:
gradient checkpointing:省显存技巧gradient checking:验梯度正确性的调试方法
这两个名字很像,但语义完全不同。
3.1.7 三者到底在改什么
- 梯度累积:改的是“一次参数更新前要处理多少个
micro-batch” - 激活检查点:改的是“前向保存多少中间激活,以及反向要不要重算”
- 梯度检查点:多数时候就是激活检查点的另一个叫法
换个更工程化的说法:
- 梯度累积主要在 时间换显存,并维持大 batch 效果
- 激活检查点主要在 重算换显存,降低 activation memory
它们解决的瓶颈并不一样:
梯度累积解决的是:batch 放不下激活检查点解决的是:层太深、序列太长、中间激活太大梯度检查点通常同上,因为它大多数时候就是激活检查点
3.1.8 三者可以一起用
它们当然可以同时开,而且大模型训练里经常一起出现。一个典型组合是:
- 小
micro-batch - 梯度累积
- 激活检查点
- 混合精度(
bf16/fp16) - ZeRO / FSDP / 张量并行
单靠一个技巧往往不够,因为显存压力来自四块:参数、梯度、优化器状态、激活。梯度累积主要压的是单次 batch 带来的激活峰值,激活检查点主要压的是中间层 activation memory,混合精度会同时影响参数和激活的字节数,ZeRO / FSDP 则更多是在参数、梯度、优化器状态的分片上做文章。
这也是为什么大模型训练里最怕的常常不是“参数本身有多大”,而是训练态下那一整套显存账本叠在一起之后,峰值会非常难看。
4 Transformer 与 LLM 架构
4.1 PostNorm 与 PreNorm
4.1.1 公式
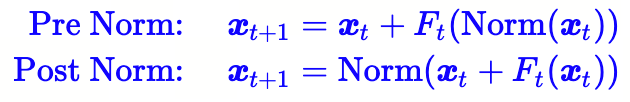
4.1.2 优劣分析
- from 苏神
- 在 Pretraining 中,Pre Norm和Post Norm都能做到大致相同的结果,但是Post Norm的Finetune 效果明显更好
- Pre Norm更容易训练,因为Post Norm要达到自己的最优效果,不能用跟Pre Norm一样的训练配置(比如Pre Norm可以不加 Warmup 但 Post Norm 通常要加)****
- 一个 L 层的 Pre Norm 模型,其实际等效层数不如 L 层的 Post Norm 模型,而层数少了导致效果变差了。(Pre Norm结构无形地增加了模型的宽度而降低了模型的深度)
4.2 MHA
- 目的:多个 head 并行计算,从不同的表示子空间学习信息
- H 个 heads,每个head 的维度为 D:
Q K V 的维度都是:【b,H,s,D】其中 H✖️D = Hidden size 。
每个 head 独立计算 attn,把结果 concat 后,乘以 Wo
4.2.1 手撕
import math
import torch
import torch.nn as nn
class MyMHA(nn.Module):
def __init__(self, hidden_size, num_heads):
super().__init__()
assert hidden_size % num_heads == 0
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = hidden_size // num_heads
self.q_proj = nn.Linear(hidden_size, hidden_size)
self.k_proj = nn.Linear(hidden_size, hidden_size)
self.v_proj = nn.Linear(hidden_size, hidden_size)
self.o_proj = nn.Linear(hidden_size, hidden_size)
def forward(self, x, attention_mask=None):
# x: [b, s, h]
bsz, seq_len, _ = x.shape
q = self.q_proj(x)
k = self.k_proj(x)
v = self.v_proj(x)
# [b, s, h] -> [b, num_heads, s, head_dim]
q = q.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# [b, num_heads, s, s]
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
if attention_mask is not None:
scores = scores.masked_fill(attention_mask == 0, float("-inf"))
attn_weights = torch.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
# [b, num_heads, s, head_dim] -> [b, s, h]
context = context.transpose(1, 2).contiguous().view(bsz, seq_len, self.hidden_size)
output = self.o_proj(context)
return output这个版本省略了 dropout、KV cache、cross-attention 和 causal mask 的细节,但已经是面试里能完整讲清楚数据流的版本。真正手撕时我会盯住四步:
- 先把输入投影成 Q、K、V
- 再拆成多头
- 每个 head 独立做 scaled dot-product attention
- 最后把所有 head 的结果 concat,再过
W_o
5 强化学习
5.1 GAE 与 PPO Loss
5.1.1 动作价值函数 Q(s, a) 和状态价值函数 V(s)
- Q(s, a):在状态
s执行动作a后,所能获得的期望累积奖励。 - V(s):在状态
s,遵循当前策略所能获得的期望累积奖励。可以理解为在这个状态下,平均能得多少分。
5.1.2 优势函数 A(s, a)
优势函数是GAE的核心。它的定义非常简单
A(s, a) = Q(s, a) - V(s)
Q:当前状态下做动作 a 的真实价值(根本不能知道)
V:当前状态的平均预期价值(底线)
所以要用一个代替品,根据贝尔曼方程,一个动作的价值等于:它带来的即时奖励 + 之后状态的价值。
$$Q(s_t, a_t) = \mathbb{E}[r_t + \gamma V(s_{t+1})]$$
$$A(s, a) \approx \underbrace{r_t + \gamma V(s_{t+1})}_{\text{实际表现的比预期好吗?}} - \underbrace{V(s_t)}_{\text{原本的底线预期}}$$
A(s, a) = Q(s, a) - V(s)所表达的含义是:在状态s下,执行动作a比遵循当前策略的平均行为要好多少。
- A(s, a) > 0:这个动作比平均动作好,应该被鼓励。
- A(s, a) < 0:这个动作比平均动作差,应该被避免。
如果我们能准确地知道每个状态动作对的优势值 A(s, a),策略优化就变得非常简单:更多地选择优势为正的动作,避免优势为负的动作。
问题是,在真实环境中,我们无法直接知道 Q(s, a) 和 V(s) 的真实值,只能通过采样(与环境交互)来估计它们。怎么估呢?有两个常用但各有缺陷的方法:
- 方法A (看全程结果): 从当前动作开始,一直算到游戏结束的总奖励(蒙特卡洛)。优点:无偏(理论上准)。缺点:方差巨大(结果受后面随机性影响太大,不稳定)。
- 方法B (只看下一步): 用当前奖励 + 对下一个状态价值的估计 - 当前状态价值(一步TD误差)。优点:方差小(只受一步随机性影响)。缺点:有偏(依赖的估计本身可能不准,且忽略了更远的收益)。”
5.1.3 GAE
- 原理和公式
把看 n 步的估计结果,加权混合
GAE 计算出的优势值
是从当前时刻 到序列结束的所有 的加权和:
在手撕代码时,为了避免
-
为什么公式里是
连在一起? 因为
是物理折扣(未来的钱不如现在的值钱),而 是信度折扣(越远的步数,我们对当前动作的“功劳认定”就越不确定)。
import torch
def compute_gae(rewards,values,next_values,masks,gamma=0.99,lab=0.95):
""" rewards: [T, B]
values: [T, B] (当前状态的价值)
next_values: [T, B] (下一状态的价值)
masks: [T, B] (done 信号,1 为未结束,0 为结束)
"""
advantages = torch.zeros_like(rewards)
last_gae_lam = 0
for t in reversed(range(len(rewards))):
delta = rewards[t] + gamma * next_values[t] * masks[t] - values[t]
advantages[t] = last_gae_lam = delta + gamma * lam * masks[t] * last_gae_lam
return advantages, advantages + values
5.1.4 PPO Loss
def ppo_loss(old_log_probs, new_log_probs, advantages, eps=0.2):
"""
old_log_probs: 采样时旧策略的 log_prob [N]
new_log_probs: 当前更新策略的 log_prob [N]
advantages: 计算好的优势函数 [N]
"""
# 1. 计算概率比率 ratio = exp(new_log_prob - old_log_prob)
ratio = torch.exp(new_log_probs - old_log_probs)
# 2. 计算两部分损失
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1.0 - eps, 1.0 + eps) * advantages
# 3. 取最小值并加负号(因为是要最大化奖励,而优化器是做梯度下降)
# PPO 还会加上 Entropy Loss 和 Value Loss,这里是核心的 Policy Loss
loss = -torch.min(surr1, surr2).mean()
return loss
6 RAG
6.1 如何评估线上 RAG 效果
- 检索层看该召回有无召回到
- Hit@k:Top-k 里命中的要找的有多少个。Hit@5<0.7 说明检索层有问题,考虑换 Embedding 模型或者优化 Chunking
- MRR:平均倒数排名,对每个问题算 1/排名,对所有问题求平均。(第一名找到 1 分,第二名找到 0.5 分,第三名 0.33 分以此类推)MRR <0.5 说明 Rerank 不好,正确内容召回了但不在前面
- 生成层看答案回答效果
- RAGAs 框架(LLM aaj):Faithfulness(>0.8较好),Answer relevancy(>0.8较好),Context Recall(>0.7较好:要回答此问题需要的多少比例在检索结果里覆盖到了 查全),Context Precision(衡量检索结果里有用的内容排名是否靠前)
- Context Recall低:换 Embedding,Chunking
- Context Precision低:召回噪音太多,加强 Rerank,调低给 LLM 的 Chunk 数
- Faithfulness低:幻觉太大,加强 prompt 约束,引入引用核查,检索质量门控
- Answer relevancy低:明确 prompt 指令
- RAGAs 框架(LLM aaj):Faithfulness(>0.8较好),Answer relevancy(>0.8较好),Context Recall(>0.7较好:要回答此问题需要的多少比例在检索结果里覆盖到了 查全),Context Precision(衡量检索结果里有用的内容排名是否靠前)
- 业务数据上
- 线上指标:点踩率,追问率,转人工率,空回答率(系统说不知道的概率),会话解决率
6.2 Chunking 相关
- 文档咋存的
- chunk 之后存,因为就算模型支持超长输入,压成一个向量也会稀释细节信息(比如时间信息,具体政策条款)
- chunk 的数据结构
- 向量(只用于向量数据库里的检索,LLM 看不懂,所以要存原文)
- 原文
- metadata(source 文件,page 页码,章节等)用于过滤和溯源
- 粒度
- 文档切割策略:适合纯文本,没用结构的文档
- 固定大小(chunk 大小可控,但不管语义边界,破坏语义完整性)
- 固定大小+重叠:一般和固定大小搭配使用,比如大小=500,overlap=100
- 语义边界切割:适合MD,HTML(可以按标题层级切)
- 维护分隔符优先级列表,先尝试段切,再尝试句切,还是太大的话按标点切直到满足 chunking size 限制
- 特殊内容(代码,表格)
- 代码:按函数或类(用 python AST 之类的语法解析工具)
- 表格:整块保留,转 MD
- 父子切割
检索用小块,返回用大块
- 同一段内容存 2 份,小份用于检索,大份用于根据小份检索出来的关联 ID 去取内容,把完整上下文交给 LLM 阅读
- 文档切割策略:适合纯文本,没用结构的文档