以 Text2SQL 为中心,围绕 Judge 模型设计 + RL 训练 + Prompt 策略 的调研。按公司/工作分组,每项只记录对我们选车 XML 场景可借鉴的点。
基于 Judge 的方法
Arize (2024-08)
Text-to-SQL: Evaluating SQL Generation with LLM-as-a-Judge
Judge 模型直接用 GPT-4 Turbo。结论:
- Spider / BIRD 基准上,不给 schema 的情况下 F1 能到 0.70-0.76;给足 schema 可以上到 0.82。
- 传统执行结果匹配(Exact Data Matching)会漏掉几类”SQL 差但执行结果一致”的坑,LLM judge 能识别出来:
- 零值分桶:
LEFT JOINvsINNER JOIN。前者保留”行政部:0 人”,后者跳过。如果测试库里每个部门都有人,两条 SQL 执行结果一样,但后者漏掉了空值边界。 - 数值舍入:
1234.5678vs1234.57(模型主动加了ROUND)。业务上常常可接受,甚至更合适,但 Exact Match 直接判错。
- 零值分桶:
Scale (RLHF for Text2SQL)
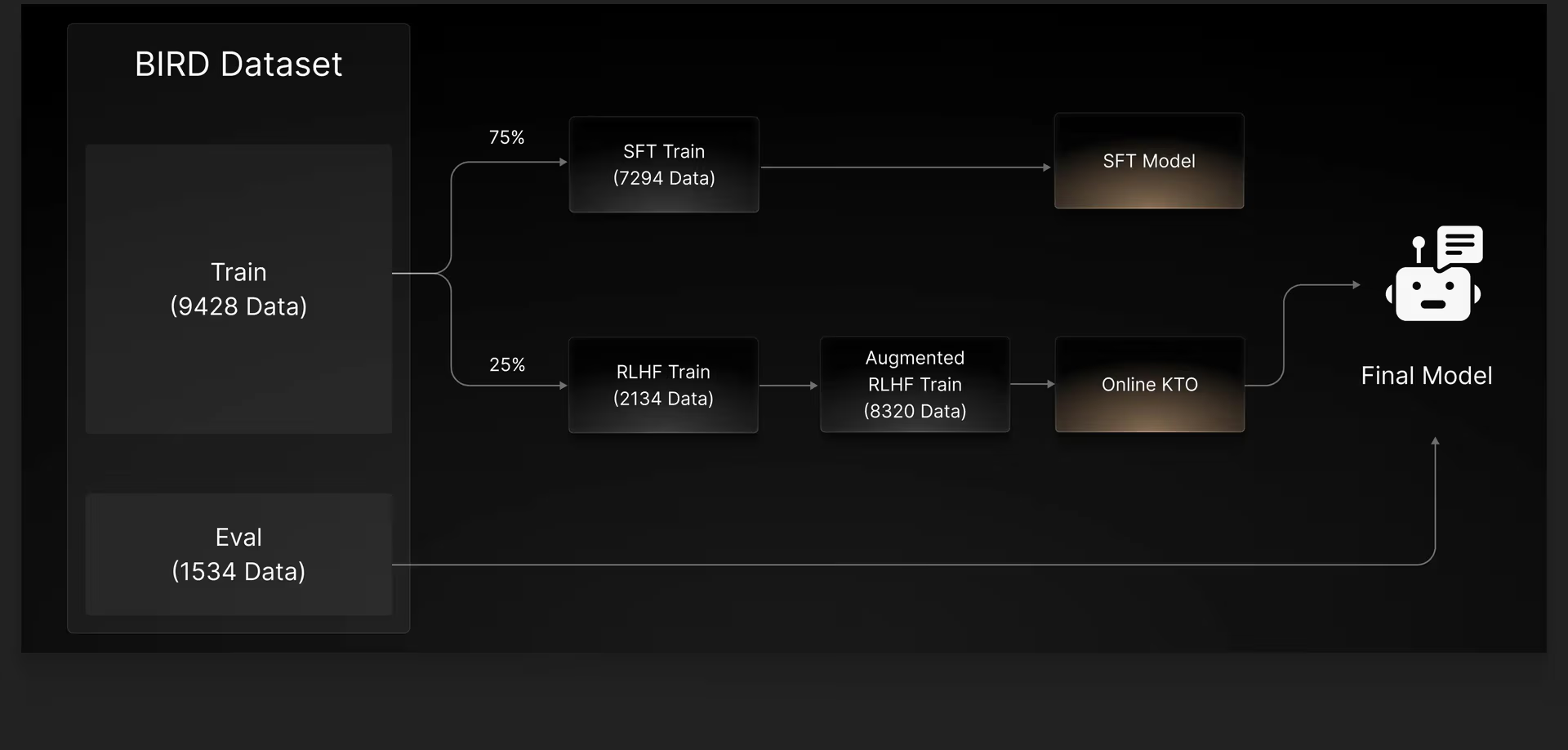
数据组织:75% 数据给 SFT,25% 留给 RLHF。RLHF 那 25% 还会做 schema shuffling 扩成 4 倍(context C1/C2/C3/C4 重排)。
RL 算法选型:在 PPO / DPO / KTO 及其 online / offline 版本里,online KTO 效果最好。
- KTO 适合数据不平衡场景。
- DPO 在特殊标记多时表现差(出自 LLaMA3 论文)。
为什么一定要留一部分数据给 RL,而不是全部 SFT 之后再 RL:如果 SFT 已经吃过所有样本,模型在 RLHF 阶段几乎不会犯错,奖励分数极度稀疏,对齐没收益。
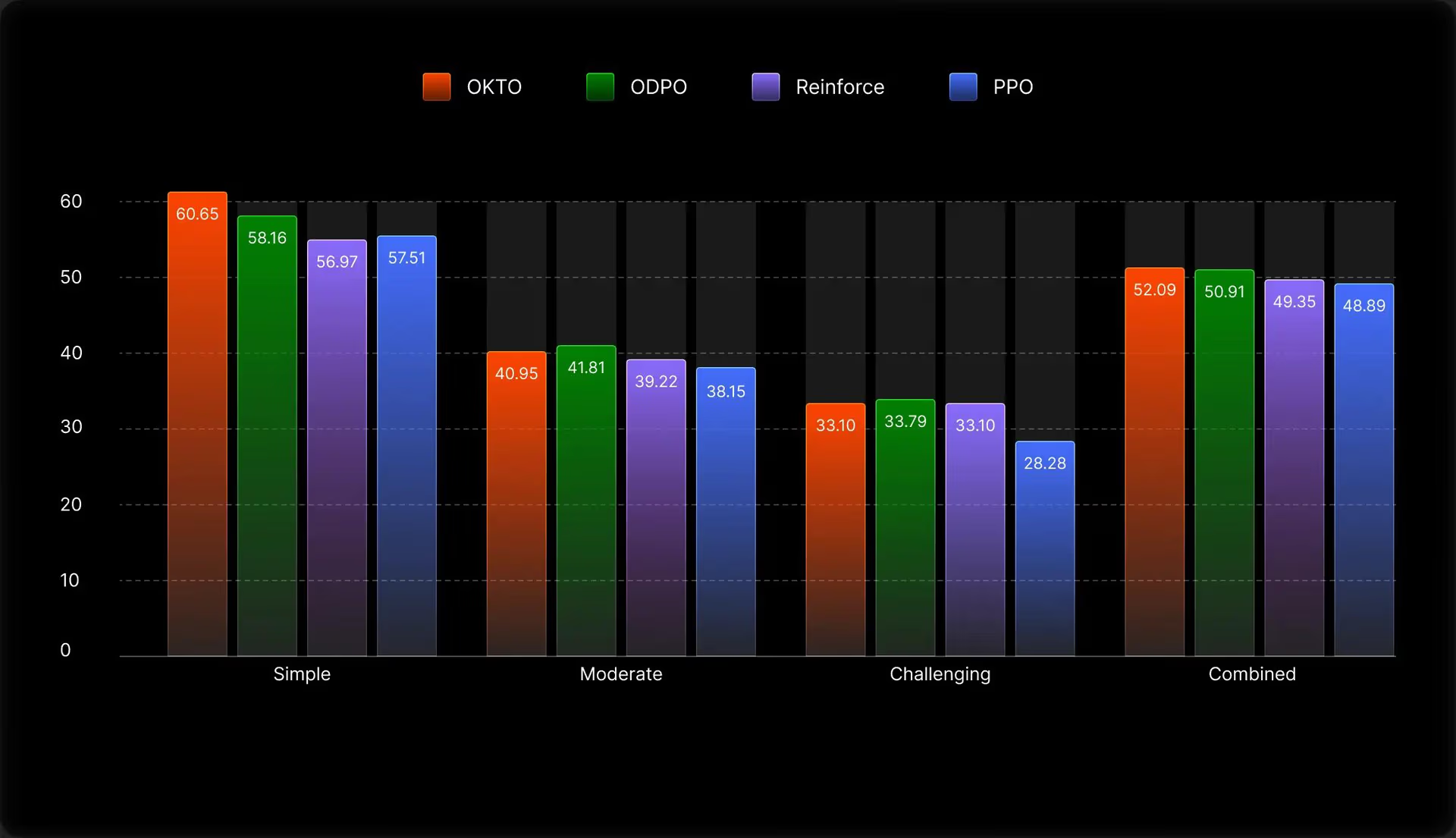
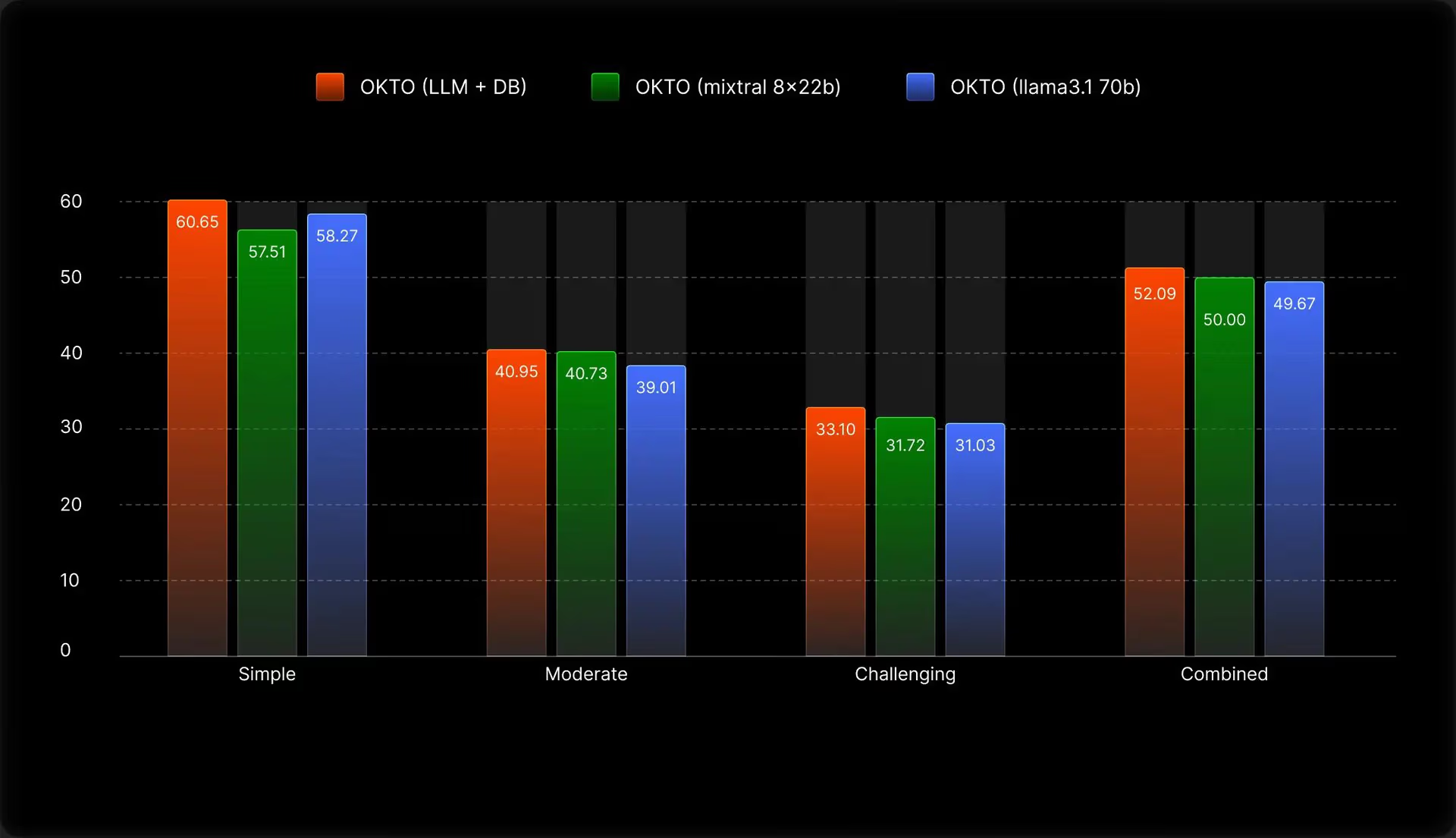
Reward 设计:LLM judge 单用或执行器单用都不够稳,但 LLM + executor 组合起来信号才有区分度。纯 LLM 无 executor 的结果见下图,可靠性有限:
小红书 QP-OneModel (2026-02)
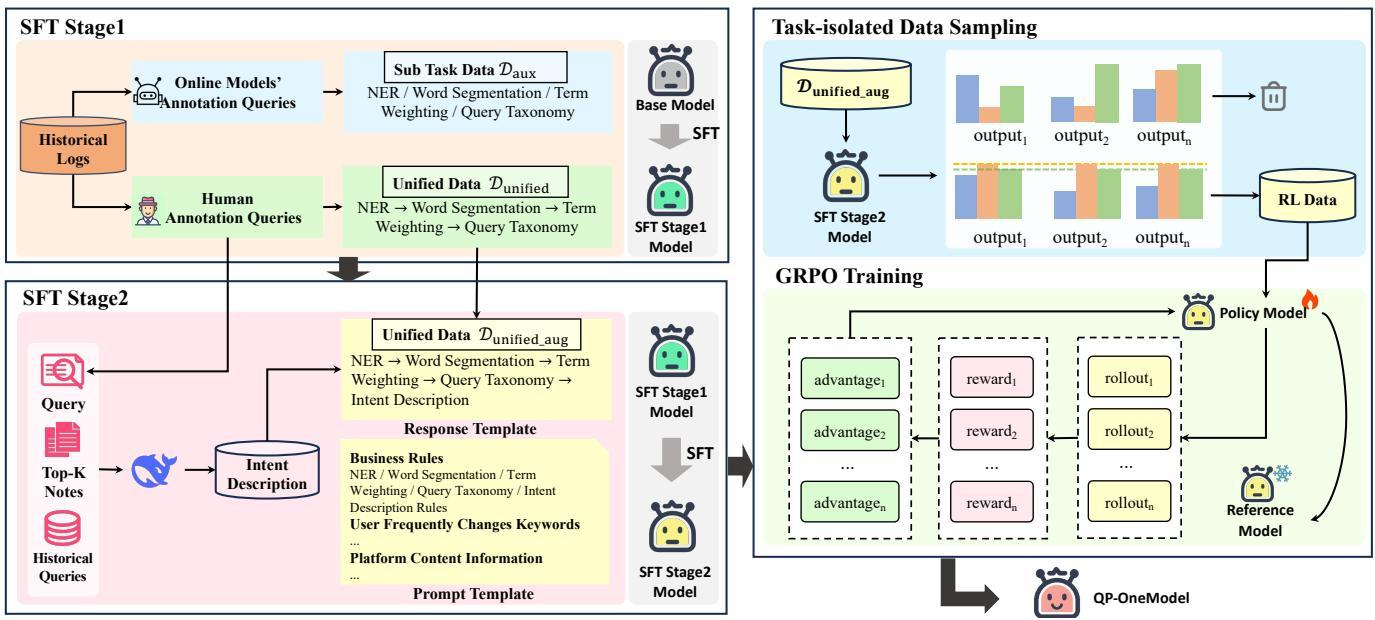
核心思路:把整个 QP 工作流重新表述成一个统一的 seq2seq 生成任务。输入 query q + 静态指令 I + 业务规则 R + 动态上下文 C,输出包含所有 QP 子任务结果的 JSON。

渐进式三阶段对齐
Stage 1:知识注入(混合 SFT)
用旧系统(Legacy Pipeline)在
Stage 2:目标分布对齐
丢掉 Stage 1 的伪标签数据,只用最新人工标注统一数据集微调。消 Stage 1 引入的噪声,对齐当前业务逻辑,同时保证 JSON 格式在所有子任务上一致且不冲突。
Stage 3:逻辑内化(RL)
SFT 应对长尾 case 时逻辑推理不够稳,上 GRPO。奖励是复合的:
快手 OpenOneRec (2026-02)
LLM-as-a-judge 部分三步:
- 信息点抽取:把描述性文本拆成带权重的信息点列表(Weighted Information Points, WIPs),每个 WIP 包含事实陈述 + 重要性评分。

- 语义匹配:把模型生成的 WIPs 与 gt WIPs 做语义匹配,分出匹配、幻觉(生成了但 gt 没有)、漏报(gt 有但没生成)。

- 加权评分:按信息点重要性和匹配质量算最终得分,对幻觉和漏报加惩罚。
一般做法 & 成本折中
完整用 LLM judge 代价太大。业界常见的省钱组合是:
- 先用执行 + 一些 cheap heuristics 过滤掉明显垃圾。
- 只对”疑难 / 高价值 / 近边界”样本调用强 LLM judge:
- EX 相同但 SQL 结构差异大的。
- EX 不同但语义可能接近(弱等价)。
- 没 gold SQL 只有
NL + schema + candidate的(我们的场景是有 gold 的,这一条可以跳过)。
Prompt 设计要点
- 给完整 schema + 必要的数据分布提示(可以复用 schema retrieval)。
- CoT 分步评价:逐字段比对 → 多维度检查。
- Few-shot 覆盖典型错误模式。
- 输出结构化判定,便于下游消费:
{
"equivalence": "strong|weak|none",
"reasons": "...",
"schema_violations": ["field_not_exist", "wrong_table"],
"logic_issues": ["direction_error", "missing_filter"]
}Judge 模型自训练
判别数据构造
正样本 + 多类型负样本。从 Arize / FLEX / LLM-equiv / TRUST-SQL 这些工作总结出来的负样本谱系:
正样本
- 来源:Spider / BIRD 等 benchmark 验证过的 gold SQL,或者内部专家审核过的高置信度 SQL。
- 可以再细分为”强等价”(完全相同结果空间)和”弱等价”(当前数据分布下等价,比如有冗余谓词)。
负样本类型
- 语法 / 执行错误:随机删括号、改 JOIN 顺序、注入不存在字段等。
- 逻辑矛盾:
>=改成<=,status='active'改成'inactive',聚合方向翻转。在特定数据集上结果可能仍然相同,但语义明显错。 - Schema 幻觉:注入不存在的表/字段;或用存在但和 NL 语义不符的字段(问”销量”却用”库存”)。
- 执行结果偏移 / 部分覆盖:漏 WHERE 条件导致 superset;漏 join 条件导致笛卡尔积;group-by 列缺失。FLEX 的设计主要就是抓这类”EX 通过但专家说不对”或”EX 没通过但其实等价”的细粒度情况。
- schema 解释错但 EX 碰巧正确:Snowflake Cortex Analyst 的案例,GPT-4o 在特定数据子集上结果看似对,但在”非连续日期”这类边界会暴露逻辑问题。适合标成”逻辑不健壮”,训练时跟普通正确 SQL 拉开。
训练集可以设计成多标签 / 层级标签:
- 一级:Correct / Incorrect。
- 二级:Incorrect 的具体类型(Syntax / Schema / Logic / Coverage)。
- Judge 输出:二分类分数 + 细粒度 error category。
提升 Judge - 专家一致性
TRUST-SQL(美团) - Dual-Track GRPO:
- 把执行奖励和 schema 奖励分开做 token-level advantage mask,让 agent 在工具交互中稳定学习。
- 加入鲁棒性指标:对 NL 做轻微改写(同义词、语序变化),看 SQL / JSON 是否保持等价。
EPGC 四阶段协议(防幻觉的结构化交互):
- Explore:用工具查元数据(表结构、外键、采样值)。
- Propose:关键认知检查点。模型必须显式列出已验证、决定使用的 schema 子集。论文里幻觉率比基线降 9.4 倍。
- Generate:基于已建议的 schema 生成候选 SQL。
- Confirm:验证执行结果后提交最终答案。
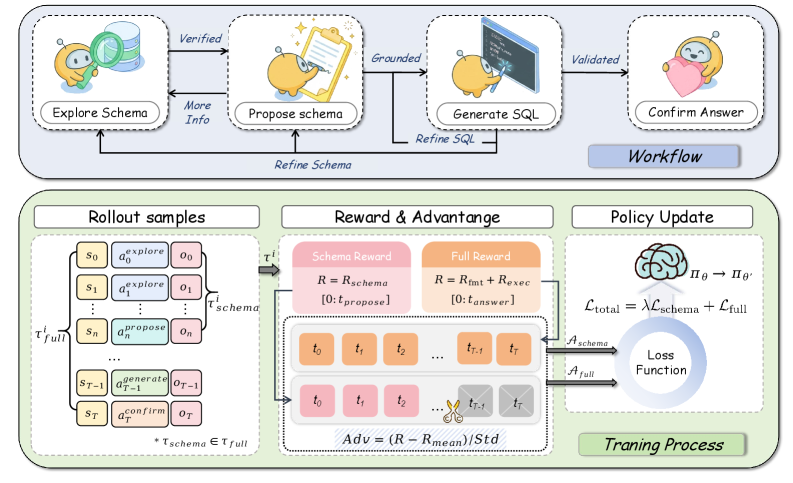
Dual-Track:Schema Track 只接收
我的结论
三步走的迁移路线:
- 前期用通用强模型(GPT-4 级)当 teacher judge,顺带产出高质量标注集。
- 中期训练自研 Judge 小模型 + RLAIF 对齐,把大部分数据过滤下沉到小模型。
- 对”小模型信心不足 / 近决策边界”的样本,继续调用强模型做二次判决。
对我们选车 XML 的场景,schema retrieval + Dual-Track 奖励这两个点最值得借鉴:前者我们已经做了,后者可以直接套到 GRPO 的 reward 设计上(schema 命中分 + validator 执行分分开 mask)。