Abstract
DeepSeek-V4-Pro(总参数 1.6T,激活 49B)与 DeepSeek-V4-Flash(总参数 284B,激活 13B),二者原生支持 1M token 上下文。相较 DeepSeek-V3.2,DeepSeek-V4-Pro 在 1M context 下 单 token 推理 FLOPs 只需 27%、KV cache 只需 10%;V4-Flash 更激进,只需 10% FLOPs 和 7% KV cache。在公开基准上,最大推理模式 DeepSeek-V4-Pro-Max 在开源模型中全面登顶 SimpleQA-Verified(57.9 vs. Kimi-K2.6 的 36.9),Codeforces Rating 达到 3206,与 GPT-5.4-xHigh 基本持平,在 CodeForces 人类选手榜上排名第 23 位----长上下文基础设施重构
技术速览
Infra
- Agent 训练依赖可执行轨迹:DSec 沙箱支持 Function Call / Container / microVM / fullVM,并记录全序 trajectory log;agent 数据的关键是可执行、可评分、可复现。
- 大规模 RL 需要可恢复 rollout:Token 级 WAL、preemptible rollout service、deterministic kernels 共同解决抢占、重跑和 batch 变化带来的训练偏差。
- 长上下文瓶颈在 KV cache 管理:分层 KV cache 和 on-disk SWA 策略说明,长上下文部署不只是 attention 算法问题,还包括 cache layout、prefix reuse 和外存管理。
- 工具调用链路也要工程化:DSML XML tool-call schema 降低 JSON escaping 错误;Quick Instruction 复用 KV cache 执行搜索判断、query 生成等前置任务,降低 TTFT。
算法
- CSA + HCA 是长上下文注意力折中方案:CSA 负责压缩后 top-k 稀疏检索,HCA 负责重压缩后的全局 dense 记忆,SWA 补局部细节。
- mHC 用约束残差提升深层稳定性:将残差变换矩阵约束到 doubly stochastic 流形,通过 Sinkhorn-Knopp 投影控制谱范数。
- Muon 仍需稳定性技巧配合:Muon 是主优化器,但 trillion-scale MoE 仍依赖 Anticipatory Routing 和 SwiGLU Clamping 控制 loss spike。
- Specialist + OPD 替代 mixed RL
- Actor-as-GRM 面向难验证任务:用 rubric-guided data 和 Generative Reward Model 替代传统 scalar reward model,适合开放式写作、办公和 agent 任务。
RL层面
后训练分两个阶段
- 分别训各领域专家
- SFT
- 在对应任务上做 GRPO
- 多专家 OPD(On Policy Distillation)
和 V3.2 的区别:用 OPD 代替了 Mixed RL 先分别训练 math/code/agent/InstructionFollowing(IF) 专家,再用 full-vocabulary OPD 蒸馏回统一 student,降低多能力混训干扰。
架构层面
- 残差连接:
Residual→ Manifold-Constrained Hyper-Connections (mHC)- 把HC的残差矩阵
约束到双重随机矩阵流形(Birkhoff polytope),相比原版 ResidualConnection、HC,解决了表达能力受限、数值不稳定的问题。
- 把HC的残差矩阵
- 注意力层:
MLA→ CSA(Compressed Sparse Attention)+ HCA(Heavily Compressed Attention)混合注意力- 交错分布(除了前两层连续HCA和最后一层压缩率为 0 的 MTP 退化成滑动窗口注意力),CSA 压缩率设置为 4 并且使用 Lightning Indexer 做top-K 稀疏KV 选择。HCA设置压缩率128、不做KV稀疏直接DenseMQA。这是DSV4实现1M上下文下,低FLOPs/KV cache的核心技术。
- CSA = 注意力层内置的细粒度实时 KV Cache RAG,负责精准抓细节;
- HCA = 注意力层内置的全局上下文摘要器,负责把握整体脉络;
- 优化器:
AdamW→ Muon(仅部分模块仍用 AdamW)- 使用Muon 10步 hybrid Newton-Schulz 正交化降低优化器开销,Embedding/Head /mHC static bias / RMSNorm 维持 AdamW。MoE expert 权重全程 FP4,CSA indexer 的 QK 路径也FP4,其余部分保持FP8。
- MoE 侧:Gate 激活从sigmoid改成
,前3个MoE层用Hash routing(按token ID 决定专家)。 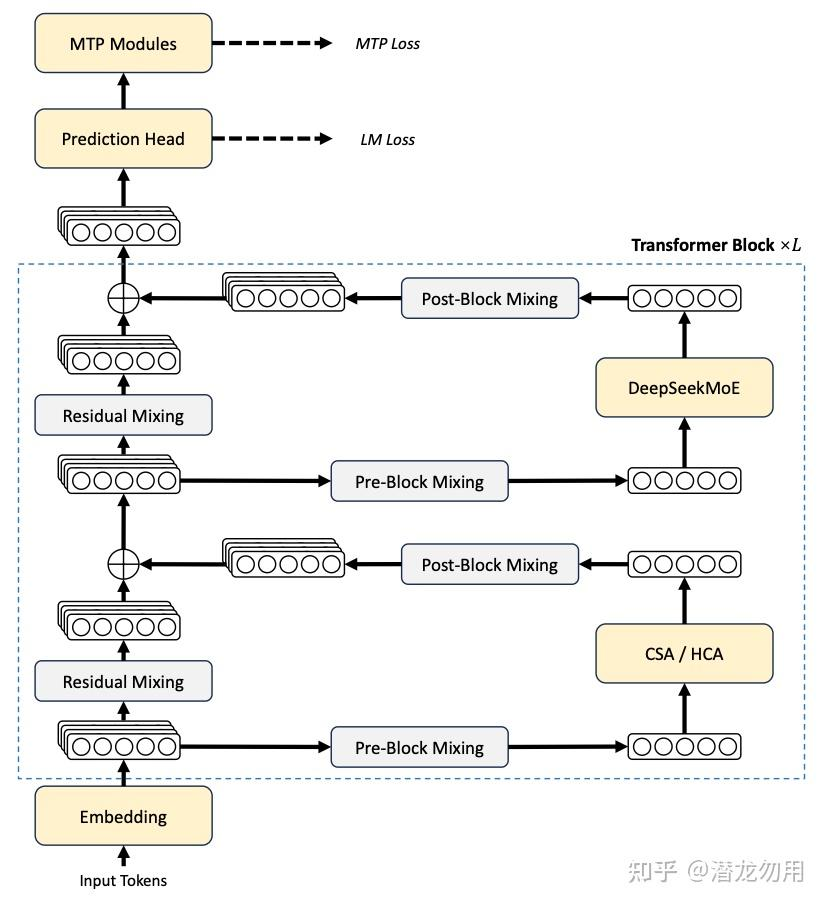
CSA
-
第一步:序列维度压缩(压缩率 = 4)
把每 4 个连续 token 的 KV 对,通过模型端到端训练学到的加权求和规则(不是简单平均,是带 softmax 权重 + 位置偏置的可学习融合,还做了重叠压缩避免硬切分的边界信息丢失—两个窗口重合一半),合并成 1 个压缩后的 KV entry。
-
第二步:Lightning Indexer 做 top-K 稀疏 KV 选择
用一个极致轻量化的低秩多查询索引器(QK 路径全程跑 FP4,开销极低),在压缩后的 250K 个 KV entry 里,给当前 query 动态选出 top-K 个最相关的压缩块(V4-Pro 里固定 top-K=1024),只有这部分被选中的 KV,会进入最终的注意力计算,剩下的全部跳过。
设计目的:用低倍率压缩保留足够的语义分辨率,再通过稀疏选择把注意力计算量砍到极致,既保证了长文本里关键细节的召回能力,又彻底避开了全量注意力的 O (n²) 成本。
HCA
-
第一步:极致序列压缩(压缩率 = 128)
把每 128 个连续 token 的 KV 对,压缩成 1 个 KV entry,压缩力度是 CSA 的 32 倍。1M token 的原始序列,这一步直接被压缩到不到 7800 个 KV entry,序列长度降到原来的 1/128,KV Cache 体积也同步降到原始的 1/128。
-
第二步:不做稀疏选择,直接 DenseMQA 全量计算
因为压缩后的序列已经足够短,哪怕做全量的稠密注意力计算,成本也极低。所以模型直接对这不到 7800 个 KV entry 做完整的 MQA 注意力计算,让当前 query 能和压缩后的全局所有 KV 做交互,拿到完整的长历史全局轮廓。
设计目的:用极致压缩换全局视野,彻底解决 CSA 稀疏选择可能丢失的全局结构、弱相关上下文信息,给模型提供长文本的整体脉络;同时因为压缩率极高,哪怕做全量稠密计算,FLOPs 和显存开销也完全可控。
细节
- 每个Head的Q、共享的KV都单独做RMSNorm防止Attn logits 爆炸
- 只对最后 64 维做 RoPE,其余 448 维走 FP8/FP4 量化
- attn sink:啥意思没看懂,给每个 head 的 softmax 分母加一个 exp(z’_h),让attn 可以选不对任何 token 施加注意力
- 每层保留 n_win=128 个未压缩的 KV,和压缩 KV 拼起来做 attn;修复 CSA/HCA 的漏洞(query 只能选择与自己不属于一个压缩块的块,看不见自己的邻居);其次让最近 tokne 相关性最强
mHC
为了解决残差连接的表达能力受限以及 seesaw 效应。也为了解决 HC 的数值不稳定和系统开销大
具体先省略