Skill 的本质
---
name: frontend-design
description: Create distinctive, production-grade frontend interfaces with high design quality. Use this skill when the user asks to build web components, pages, artifacts, posters, or applications (examples include websites, landing pages, dashboards, React components, HTML/CSS layouts, or when styling/beautifying any web UI). Generates creative, polished code and UI design that avoids generic AI aesthetics.
---
This skill guides creation of distinctive, production-grade frontend interfaces that avoid generic "AI slop" aesthetics. Implement real working code with exceptional attention to aesthetic details and creative choices.
...一条 Skill 本质上是按需加载的 prompt + 模板 + 脚本包:一个带 YAML frontmatter 的 SKILL.md,外加可选的脚本、参考文档、模板。Claude 启动时只加载 name + description(几十 tokens),只有当任务匹配 description 时才会把完整内容读进上下文。它解决的是”我有一堆领域知识/流程,但不想常驻 context”这个问题。
Skill 不用向量召回,是因为要保留组合性。 把所有 Skills 的 frontmatter 常驻上下文,是为了让大模型自己决定”这个任务要调单个 Skill 还是若干 Skill 组合”,而语义相似度召回会偷偷替你做掉这个决策。Skill 过多担心上下文膨胀时,更干净的做法是单独挂一个 Flash / Lite 的小模型专门负责 Skill 挑选。
关键机制
- 渐进披露(progressive disclosure):SKILL.md 是入口,内部再
Read其他文件。不要把所有东西塞进 SKILL.md。DeerFlow 的官网上我用一个动画形象地演示了这个过程。 - description 是唯一的触发器:写不好就永远不会被调用。至少包含”什么时候用 + 用来干什么”两个维度;歧义大的场景还要写清楚”什么时候不该用”。
- Skill ≠ Prompt ≠ Agent ≠ Hook:Skill 是知识/流程;Agent 是独立上下文的子进程;Hook 是确定性触发的 shell 命令。自动化行为(“每次 X 都要 Y”)应该用 Hook,不是 Skill。
写 Skill
用什么写
用 AI 写,给 AI 看。
更准确地说:用最贵的模型编写(Claude Opus),这样才有机会用更便宜的模型(Sonnet)执行这个 Skill。中文还是英文交给 AI 自己决定,通常是英文为主。编辑器最好的选择就是 skill-creator 这个 Skill 本身——主流 AI 工具大多内置,直接 /skill-creator 拉起。
下面是一条示例需求,给个手感:
/skill-creator 帮我实现一个技能,根据当前仓库的现有代码,提取出典型的团队代码风格:
1. 首先,通过文件树摸清这个仓库的主要编程语言,然后 propose 几个你认为最重要的文件。这些被挑选出的文件个数不能低于 3 个或多于 10 个,这些文件应该足以让你将了解团队代码的基本风格,同时尽可能的涵盖了项目中不同的编程语言、不同的架构层(配置、数据访问、API 暴露、Thrift 定义等)
2. 提取出团队代码的文件夹、文件、方法、成员、类型命名的规律(允许一个类别下有不同的命名方法),细致到例如分页器的参数是如何命名的
3. 作为 Coding Agent,你应该比团队还要更加了解自己的代码风格,而不是事无巨细的列出大家都知道的 rules(token-saving),才足以体现出你的价值
4. 总结为简明扼要的、方便 AI 理解而不是人类理解的 markdown 文档:docs/code-convention.md什么时候做渐进式披露
通常把参考资料(reference)、示例(example)、模板(template)和脚本(Node.js / Python script)作为 Skill 渐进式披露的零件。在 /skill-creator 生成了一个庞大的 Skill 之后,我通常只说一句:
当前 SKILL.md 太长了,缺乏 progressive-disclosure 机制,但是也请不要滥用。
剩下的事情就交给 AI。它会把模板和示例拆到对应目录的 markdown,把 switch...case 式的大逻辑分支拆成独立文件——只有命中条件的分支才会在运行时被加载。
如果 Skill 里有”机械式”的逻辑,skill-creator 也会主动用 Node.js 或 Python 实现,避免这些环节出现幻觉或漏执行。你也可以直接点名:
Skill 里可以”机械式”执行的部分(如果有)请帮我用 Python 实现。
保留 Human-in-the-Loop
好的 Skill 应该适度引入 Human-in-the-Loop。可以在 Skill 的 prompt 里明确要求它用 AskUserQuestion 和用户多轮交互。AskUserQuestion 本身支持单选、多选、带预览的单选,以及 step-by-step 式的向导。
持续迭代 — Agent RL
用 Claude Code 跑 /skill-creator 的过程,其实就是:生成 → 在真实任务里用 → 失败或别扭的地方反馈 → 让 skill-creator 改 SKILL.md。每一轮都是一次人工 RLHF。
skill-creator 自带 eval 能力,生成完 Skill 后直接跟它说:
Run evals on this skill with your mocked test cases, and I’ll return you with my feedback via the Eval Review web page you provided
Claude Code 会自动生成测试用例,并用多个 Sub-agent 并行评估:
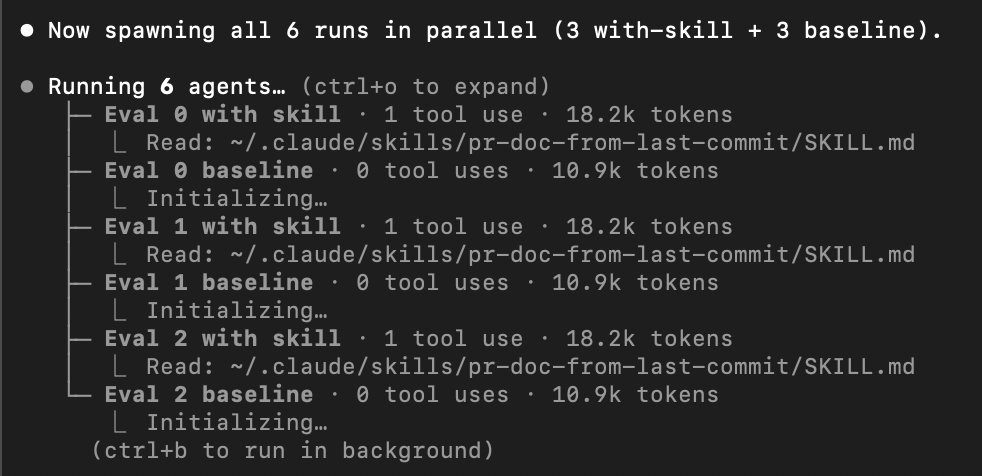
评测完成后会生成一个 Eval Reviewer 页面,能对比”用 Skill”和”不用 Skill”的输出差异。
来自 claude-api 的启示
看看 claude-api 这条 skill 的写法,就是本文反复讲的那套模式。歧义越大的场景,反例越重要。几条我觉得值得抄走的:
- 先写”能跑的例子”,再抽象成 skill:先让 Claude 手动完成一次任务,把过程记下来,再对 skill-creator 说”把这段流程固化成 skill”。从具体到抽象,比凭空写效果好得多。
- 大知识拆文件,SKILL.md 只放索引:SKILL.md 里写”详细 API 参考见
reference/api.md,模板见templates/”,Claude 需要时会自己去读。SKILL.md 本身最好控制在 100 行内,因为它每次都要过一遍。 - 脚本优先于 prompt:某个子步骤是确定性的(格式转换、校验、调 API),写成
scripts/xxx.py让 skill 去执行,比用自然语言描述可靠一个数量级。skill-creator 默认偏好 prompt,需要你主动说”这步用 Python 脚本实现”。 - 用
allowed-toolsfrontmatter 收窄权限:在 SKILL.md frontmatter 里限定allowed-tools: Read, Grep, Bash(git log:*),避免 skill 在不该动手的场景乱改文件。skill-creator 不会主动加这条,需要你提。 - 先写 eval,再写 skill:让 skill-creator 先生成 5–10 个测试 prompt(带预期行为),再让它写 SKILL.md,最后跑 eval 对齐。这就是前面提到的 RL 循环的自动化版本。
并行多任务
什么样的任务适合并行
我最近在为一个通用 EDA(Exploratory Data Analysis)Skill 设计执行架构时深入想了这个问题。EDA 就是给 Agent 一个 CSV 或 Excel,让 AI 不断自己命题、自己编写并执行 Python 代码做查询和统计,在认为足够了解数据后写出最终报告——标准的 Code-act 过程。从这个 case 出发,并行子任务的价值可以拆成三个维度:性能、隔离、多样性。
EDA 是什么:探索性数据分析(Exploratory Data Analysis)——在你建模、下结论之前先让数据说话。它没有固定流程,核心是用统计 + 可视化快速摸清数据的长相:多少行列、分布是否正常、哪些字段高度相关、哪里有缺失或异常。EDA 的价值不在给出答案,而在帮你问出正确的问题。
下面是 EDA Skill 的两种架构对比,分别是串行和并行:
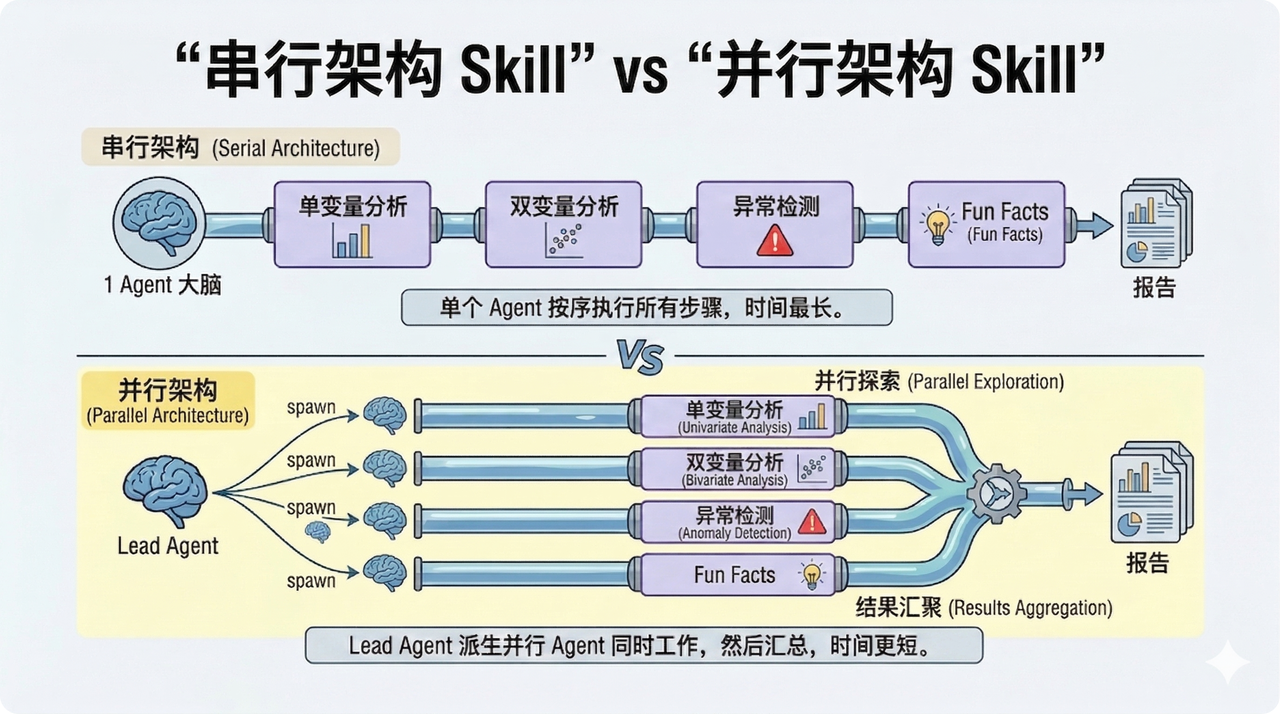
性能
单 Agent 串行执行时,每一步推理都要等上一步完成。对一个典型的 EDA 任务来说,单变量分析、相关性计算、异常检测、趣味发现挖掘四块工作之间几乎没有数据依赖——串行总时间是四块之和,并行取决于最慢的那块,理论上接近 4 倍加速。
这不是理论推演。M1-Parallel(2025 年 arXiv)在复杂推理任务上实测了并行多团队执行的效果,报告了高达 2.2 倍的端到端加速且准确率不掉。Anthropic 在 Research 系统内部评测里也观察到,多 Agent 架构(Claude Opus 4 领衔 + Claude Sonnet 4 子 Agent)相比单 Agent Claude Opus 4,研究任务表现提升了 90.2%。
更深层的性能优势在智力密度(intelligence density)。Anthropic 的分析里有一个信号很强的数字:在 BrowseComp 评测中,token 使用量单独就能解释 80% 的性能差异。换句话说 Research 任务的质量几乎正比于投入的计算量,而多 Agent 并行的真正价值,是在相同墙钟时间内塞进数倍 token——也就是数倍”思考量”。代价是很烧钱。
上下文隔离
LLM 的上下文窗口是稀缺资源。塞得越多,注意力越散,推理质量越退化。LangChain 的官方文档给过一个很干净的对照:在比较 Python、JavaScript、Rust 的任务里,Subagent 模式(每个子 Agent 只加载自己需要的 2000 token 文档)总共消耗约 9K token;Skills 模式(所有文档塞进同一个上下文)膨胀到 15K token。子 Agent 模式的 token 消耗减少 67%。
上下文隔离在三层面上起作用:
注意力聚焦:子 Agent 只负责”异常检测”这一件事,它的整个上下文窗口都被异常检测相关的数据、代码输出、推理过程占据。它不需要”记得”相关性分析的中间结果,也不需要”忽略”Fun Facts 挖掘过程中产生的噪音——等于有一间干净的屋子,心无旁骛地干活。
降低上下文污染:长序列推理里,前面步骤的错误会像传染病一样向后扩散。一个统计计算的小错误可能让后续异常检测产生误判,误判又可能污染最终的 Fun Facts。并行执行天然切断了这条错误链——每个子 Agent 从干净状态出发,互不干扰。
延长有效工作时间:Claude Code 的子 Agent 设计是经典案例。主 Agent 把需要大量阅读和搜索的调研类任务交给子 Agent。子 Agent 做完后只返回结论而不是把整个调研 trace 灌回主 Agent,主 Agent 上下文保持精简,能持续工作更长时间而不触顶。
多样性
多条路径同时展开,总有一条能找到最优解。
这正是 M1-Parallel 框架的核心思路:并行运行多个 Agent 团队,每个团队独立规划、独立执行,再通过 early termination 或 aggregation 策略选最佳结果。实验显示,即使不刻意引导团队走不同路径,单纯依靠 LLM 采样的天然多样性,并行执行就能显著提升任务完成率。
EDA 场景里这种多样性非常具体。就以 Fun Facts 挖掘为例,不同子 Agent 可能从完全不同的角度切入数据:一个发现了时间维度上的异常分布、一个发现某个分类变量的 Zipf 定律偏离、第三个注意到两列之间出人意料的负相关。单 Agent 串行执行大概率只会拿到最”主流”的那一两个发现——因为模型的注意力被前序结果锚定(anchoring effect),很难跳出既有的思维框架。
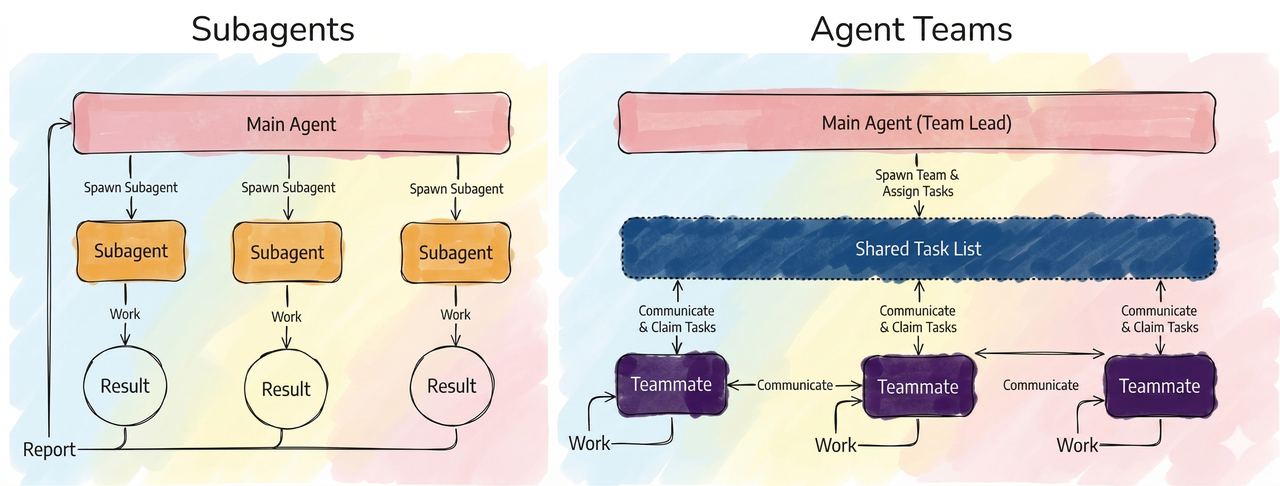
Sub-agent vs Agent Team:既然能综合四个 Sub-agent 的视角,是否还能让不同 Agent 互相辩论?可以,这时候你需要在 Claude Code 里开启 Agent Team(实验功能)。让它们先吵架再合并结论,让背后跑着不同模型、不同 prompt 的 Agent 一起讨论,确实能得到更全面、更值得推敲的结果。唯一的缺点是非常烧 token。
多样性的价值在阅读型任务远大于写作型任务。这也是 Anthropic 和 Cognition 看似矛盾实则一致的原因——Anthropic 做 Research(阅读、搜索、综合),Cognition 做 Coding(写代码、修 bug、集成)。Research 天然适合并行探索,搜索空间大且方向互不干扰;Coding 对一致性要求极高,并行写出来的代码片段容易互相冲突。不同场景需要不同工具。
何时不该并行
三种应该谨慎使用并行的场景:
子任务之间存在强依赖:子任务 B 的输入依赖 A 的输出时,并行就失去意义。EDA 里”数据加载”和”数据质量审计”就是这种关系——必须先成功加载数据才能审计质量。我在 EDA Skill 里把 Phase 0(加载)和 Phase 1(质量审计)做成串行,Phase 2(深度分析)才展开并行。
子 Agent 之间需要”商量”:Cognition 的核心批评就在这里。多个子 Agent 需要执行过程中互相协调——比如两个 Agent 写的代码要合并到同一个代码库——并行就会产生冲突。今天的 LLM 还不擅长这种跨 Agent 的实时协商。Cognition 的原话很有画面感:这就像让两个从未见过面的工程师各写一半代码,指望第三个人能把它们拼在一起。
上下文共享不充分:如果 Lead Agent 给子 Agent 的任务描述太笼统——比如只说”研究半导体短缺”而不指定哪个时期、哪个细分市场——多个子 Agent 很可能做大量重复工作。Anthropic 早期开发就踩过这个坑。解法是 Lead Agent 在 spawn 子 Agent 时必须提供非常具体的任务描述:调查目标、输出格式、使用的工具、明确的任务边界。
如何在 Skill 中提示并行
通过 skill-creator 创建 Skill 时,可以这么启发 Agent 用并行:
为提高效率,应显式使用 spawn 这个单词来启发模型启动并行子任务(如单变量分析、双变量分析、数据质量检查、Fun Facts 挖掘等同步推进)。在 SKILL.md 的 Frontmatter 里显式添加
allowed-tools: Agent Task。使用多任务运行时可遵循”先并行、再串行、再并行、再串行”的模式,并行任务之间应尽量独立不依赖。如果用户开启了CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS,则 Agent 之间可以协作。
spawn 是程序员熟悉的动词,通常指生成、创建或启动一个新的独立执行单元。Frontmatter 指 SKILL.md 文件头夹在两个 --- 之间的内容,allowed-tools 属性提示 Agent 可以使用哪些工具(空格分隔)。其中 Agent 是 Claude 给 Sub-agent 多任务用的工具,Task 是老版本中的名字——不少其他 Agent 因为历史原因还叫 Task。
Skill 示例 — EDA
/skill-creator 我想设计并实现一组通用的 CSV/Excel 数据源的 Exploratory Data Analysis Skill。Skill 用英文撰写。
# Steps
- 通过 Code-Act Loop(短期 Planning → 执行 → 观察 → 迭代)驱动分析过程,而不是固定的 Workflow
- 使用 Pandas / NumPy 做数据处理和统计计算
- 使用 Mermaid 做数据可视化(嵌入 Markdown)
- 最终产出一份 支持 Mermaid 的 Markdown 富文本报告,包含:
- 数据基本面(规模、类型、缺失值等)
- 发挥 EDA 和 Code-Act Loop 的特长,根据数据灵活决定内容,而不是固定的版块
- Fun Facts(数据集中有趣或反直觉的发现)
- 推荐下一步探查的方向
# 强调多任务
- 为提高效率,分析阶段应显式使用 spawn 这个单词来启发模型启动并行子任务(如单变量分析、双变量分析、数据质量检查、Fun Facts 挖掘等同步推进)。在 SKILL.md 的 Frontmatter 里显式的添加 allowed-tools: Agent Task。
- 其中,第 2 步是可以用多任务进行的,可以"先并行,再串行,再并行,再串行"的模式。注意并行的任务之间应当尽量的独立不依赖。
- 如果用户开启 `CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS`,则 Agent 之间可以协作。子 Skill
当某个子任务本身足够复杂——有自己的工作流、自己的参考文件、甚至自己的 Code-Act 循环——硬塞在主 Skill 里就开始显得拥挤。更好的做法是把复杂子任务独立成子 Skill,主 Skill spawn 子 Agent 时指定用哪个 Skill 来执行。
这本质上是 Skill 层面的分而治之。主 Skill 扮演 Orchestrator,只负责任务分解和结果汇总;每个子 Skill 是自包含的专家模块,有自己的 SKILL.md、references、甚至 bundled scripts。子 Agent 被 spawn 出来后加载对应的子 Skill,在自己的上下文里独立完成工作,最后把结果交回主 Agent。
这么切有三个直接好处:子 Skill 可以独立迭代——改异常检测的逻辑不必动主 Skill;子 Skill 可以跨场景复用——同一个 financial-analyzer 既能被 EDA Skill 调用,也能被用户直接触发;天然实现 Progressive Disclosure——主 Skill 只需要知道子 Skill 的名字和职责,不需要把子 Skill 的完整指令加载进自己的上下文。
以 EDA Skill 为例。Phase 2 的四个子任务里,“Fun Facts Mining”其实可以做得非常深——需要检测 Zipf 分布、计算 Benford 定律偏离度、搜索”历史上的今天”和数据中日期的巧合、甚至用一些假设检验来验证”反直觉”程度。这些逻辑写在 EDA Skill 里会让主文件膨胀,也会让其他三个子任务的指令被 Fun Facts 的细节淹没。
解法是把它独立成 /mnt/skills/user/fun-facts-miner/SKILL.md:
fun-facts-miner/
├── SKILL.md # 主指令:Fun Facts 挖掘工作流
└── references/
└── statistical-tests.md # 参考:可用的统计检验方法主 Skill 里关于 Fun Facts 的指令就只剩这几行:
#### Sub-task D: Fun Facts Mining
Spawn a new sub-agent, and use `/fun-facts-miner` to execute. Pass the following context to the sub-agent:
- The loaded DataFrame (saved as a parquet file at a known path)
- The data quality summary from Phase 1
- The target: produce 5–8 fun facts, each citing a specific number
The sub-agent will return a structured Markdown section that can be directly embedded into the final report.至于细节——用哪些统计检验、怎么判断”反直觉”、输出格式的完整规范——都封装在 fun-facts-miner 的 SKILL.md 中。
这套模式的关键语法是 use /{skill-name}——告诉 Agent 运行时 spawn 子 Agent 时去加载指定的 Skill 文件,而不是使用内联指令。这就像人类团队里的一种分工约定:主管说”这个子项目交给张工,按他自己的 SOP 来做”,而不是”交给张工,具体步骤是第一步……第二步……”。
当然并非所有子任务都值得独立成 Skill。我的判断标准是:一个子任务的指令超过 100 行,或者在其他场景也有独立使用价值,就值得拆出去。
如果用了 Agent Team,也可以用同样的方法提前设计需要哪些 teammate。也可以把分工完全交给 Agent 临时决定,代价是运行时需要始终挂着更高级的模型(如 Claude Opus 4.6)。
设计并行 Skill 的三条要点
回到 Skill 本身,设计并行任务时有三条容易被忽视的实操点:
在 Skill 的元数据中显式声明并行能力。在 SKILL.md 的 frontmatter 里把 Task、Agent 或你的框架里对应的并行工具写进 allowed-tools——这是给模型的”许可信号”,不显式声明一些模型就不会主动并行。正文里也要用 spawn 这样的动作词去触发模型的并行意识。
为每个子任务提供足够具体的指令。Anthropic 踩过的坑值得所有人引以为戒:模糊的子任务描述会导致重复工作。好的子任务描述包含四要素——目标(做什么)、边界(不做什么)、输出格式(返回什么)、工具指导(用什么工具)。
设计好 fan-out / fan-in 的接口。fan-out 是 Lead Agent 如何把任务分发给子 Agent;fan-in 是子 Agent 如何把结果返回。两者都需要明确的数据契约。我在 EDA Skill 里给每个子任务定的输出规范是”至少 2 个 Mermaid 图表 + 文字洞察”,Lead Agent 在 Phase 3 按固定报告模板把这些素材组装成最终报告。
# 目录结构
MySkill/
├── SKILL.md # 必填!技能的灵魂(使用说明书)
├── scripts/ # 可选!放你的业务代码(Python/Node.js/Go都可以)
│ └── main.py
└── references/ # 可选!放一些长篇的补充文档(防 SKILL.md 太长)
# Skill.md
# 头部---部分,必须是YAML格式的元数据,用来让大模型识别它。正文则是教大模型怎么用你的Skill。
---
name: my-first-skill
description: 当用户需要查某某数据时,使用这个技能。
---
# 使用指南
1. 当你需要查数据时,请明确要求用户提供 user_id。
2. 然后执行以下命令去获取数据:
`python scripts/main.py --user_id <user_id>`
3. 拿到结果后,请用表格形式回复给用户。