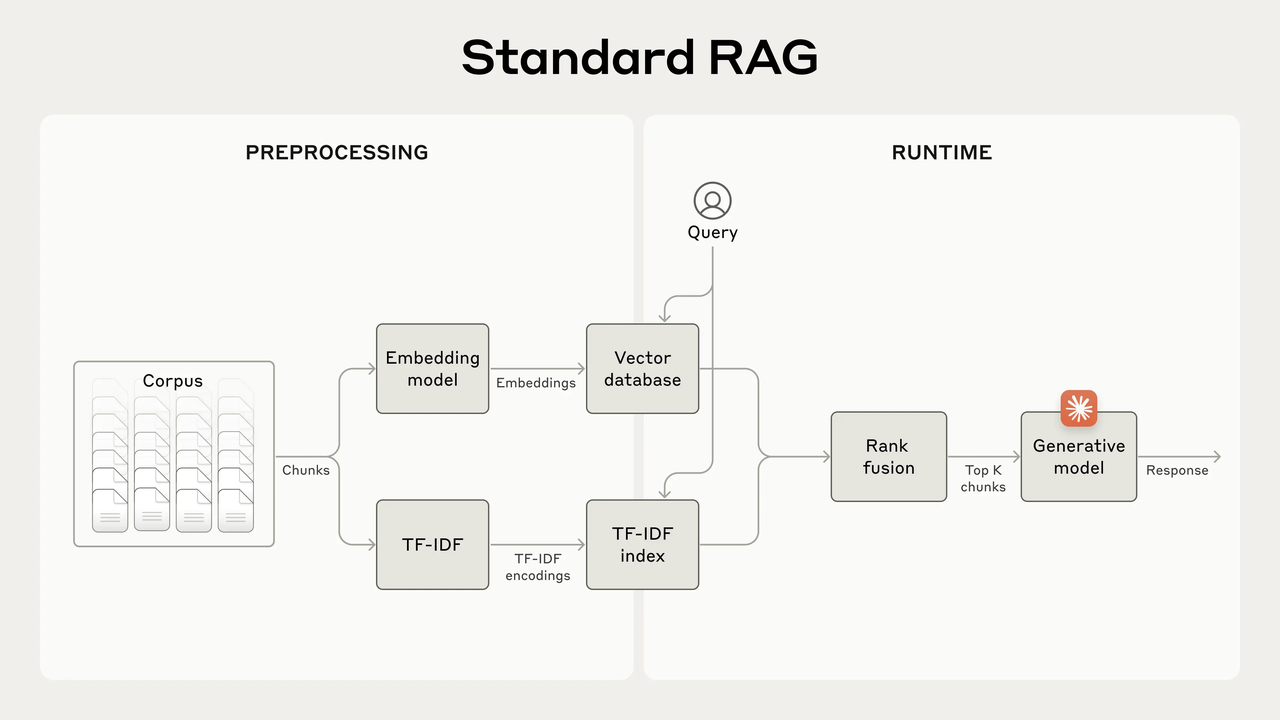
一个标准的RAG系统应该有五步流程:
相关实践文档:企业级 RAG 系统设计
离线阶段:
- 文档切分:将文档的“语料库”切分成更小的文本块
- 文本向量化:用语义模型将文档转换为高维向量
在线阶段:
- 向量检索:通过embedding去查找语义相似度最高的topK文本
- 构建Prompt:将用户的原始问题和检索到的文本构造成结构化的Prompt
- 生成回答:通过大语言模型生成最终输出
长上下文为何挑战 RAG?
“RAG 已死”的论调主要源于两股力量的交织:
- 模型自身能力的飞跃
- 对传统 RAG 固有缺陷的普遍失望。
上下文窗口的“暴力美学”
支持“RAG 已死”的最直观论据,来自模型能力的跨越式发展。当 Google 的 Gemini 1.5 Pro 提供 100 万 token、Anthropic 的 Claude 3 系列支持 200K token,乃至 Llama 4 Scout 突破 1000 万 token 的上下文窗口时,“将整个知识库装入上下文”从想象变为了技术上的可行选项 。
这种简单直接的方案非常具有吸引力。如果模型能在单次推理中“阅读”数十本书籍的文本,那么传统 RAG 中那些复杂的工程步骤——如精心设计分块策略、构建向量索引、调优检索算法——似乎都变得多余。“直接把所有内容喂给模型,让它自己找”,这种想法俘获了许多人的心 。
Naive RAG 的“级联失败”
与此同时,第一代 RAG(通常被称为 Naive RAG)在实践中暴露的结构性缺陷,也让许多开发者感到沮丧。技术评论人 Nicolas Bustamante 将其总结为“级联失败”
Each stage compounds the errors of the previous stage. Beyond the complexity of hybrid search itself, there’s an infrastructure burden that’s rarely discussed.
这些缺陷主要包括:
- 分块破坏语义:无论是按固定长度还是按段落分块,都容易切断跨越多个块的语义关联,导致检索出的信息片段上下文不完整。
- 向量检索的局限性:基于语义相似性的向量检索,天然无法很好地处理需要精确匹配的场景,例如查询特定代码变量名、函数名,或进行带有精确数值条件的过滤(如“Q3 营收是否超过 5000 万美元”)。
- 多跳推理的脆弱性:对于需要综合多个文档信息才能回答的复杂问题,Naive RAG 需要进行多轮检索,而每一轮检索的微小偏差都可能累积,导致最终推理偏离轨道。
正是这种在长下文的push和对结构性缺陷的不断放大中,“RAG is Dead”的情绪被带动起来,但是真的是这样吗?
长上下文的现实局限
面对“长上下文替代 RAG”的论断,最有效的回应是来自多项独立研究的量化数据。这些研究从准确率、成本和延迟等多个维度,系统性地揭示了长上下文方案并非“银弹”。
准确率陷阱
将海量信息一次性喂给模型,模型真的能有效利用吗?答案是否定的。
首先是著名的“Lost in the Middle”现象。 斯坦福大学的一项权威研究发现,当关键信息被放置在长文档的中间位置时,模型的回答准确率会发生戏剧性的 U 型下降 。与位于文档开头或结尾的信息相比,中间位置信息的准确率最多低 18 个百分点。这意味着,即便所有相关文档都在上下文中,模型也可能系统性地忽略掉那些藏在中间的关键细节。
其次,上下文越长,性能衰退越明显。 Databricks 团队进行了超过 2000 次系统性实验,结果显示,随着上下文长度的增加,模型的信息提取能力显著下降。例如,claude-3-sonnet 模型在 16K token 上下文长度下的准确率为 0.668,而在 125K token 下则降至 0.485,降幅超过 27% 。
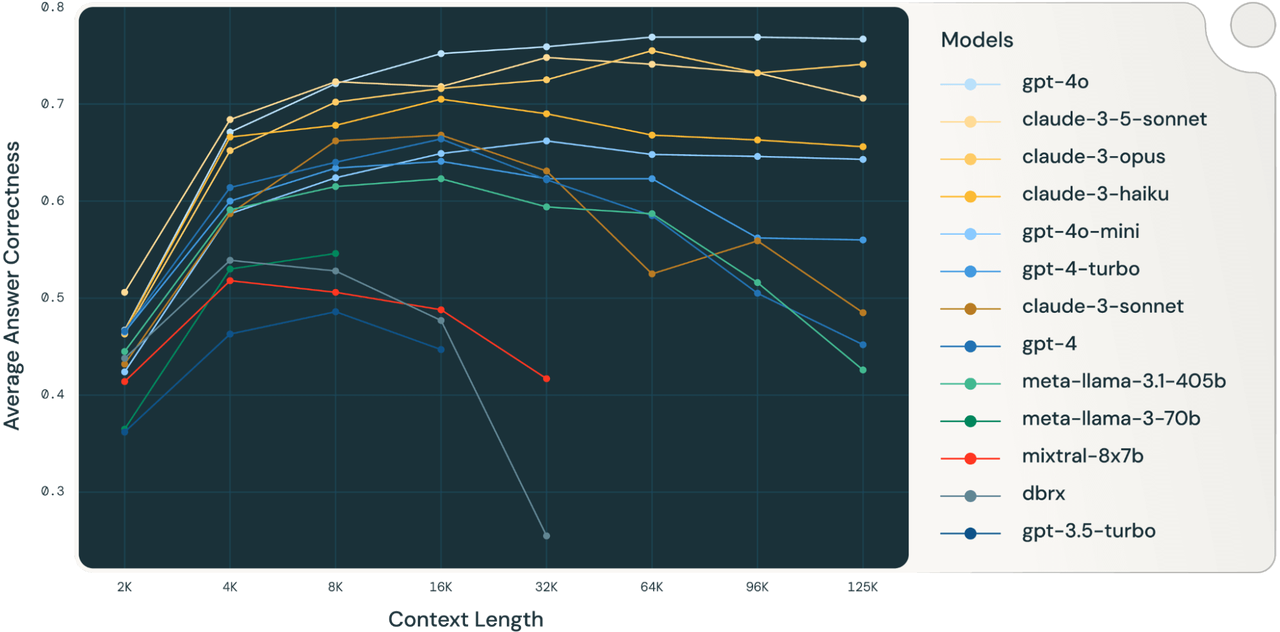
向量数据库公司 Chroma 也提出了“上下文腐烂”(Context Rot)的概念,指出广泛使用的“大海捞针”(NIAH)测试高估了模型在真实复杂任务中的长上下文处理能力 。

成本与延迟的矛盾
除了性能问题,成本和延迟也是长上下文方案在生产环境中难以逾越的障碍。量化对比显示得非常直观:
| 方案 | 单次查询成本(估算) | 首 token 延迟 | GPU 需求 |
|---|---|---|---|
| RAG 标准查询 | ~$0.020 | 1–3 秒 | ~2 块 A10 |
| GPT-4 Turbo 128K 满载 | ~$1.28 | 5–15 秒 | — |
| 1M token 长上下文查询 | ~$15 | 20–30 秒 | ~40 块 A10 |
可以看到,一次百万 token 的长上下文查询,其成本可能是标准 RAG 查询的 10 到 150 倍,延迟也长达数十秒,所需的 GPU 资源更是相差一个数量级。对于需要高并发、低成本运行的企业级 AI 应用,这在经济上几乎是不可行的。
Twitter上的用户有一个形象的描述:
Claiming that large LLM context windows replace RAG is like saying you don’t need hard drives because there’s enough RAM
这句话精准地揭示了长上下文的本质:**它是一种宝贵的运行时资源(内存),而 RAG 则扮演着高效的外部存储(硬盘)角色。**它们有不同的功能,应该作为一个系统协同工作。
-
从检索增强到上下文工程
我认为RAG为什么“未死”的关键是:它经历了一系列深刻的范式演进,最终融入一个更宏大的框架——上下文工程(Context Engineering)。Context Engineering 的目的就是为了在有限的上下文窗口内,将尽可能多的、尽可能正确的信息填充到这个窗口内。
要理解这场范式革命,我们需要回顾 RAG 技术的完整演进路径:Naive RAG → Advanced RAG → Modular RAG → Agentic RAG → Context Engineering。每一次跃迁,都是对前一代核心局限的系统性回应。
Naive RAG → Advanced RAG:修补pipline的每一环
前文所述的 Naive RAG 的”级联失败”催生了第一轮系统性改进。Advanced RAG 引入了 “Rewrite-Retrieve-Rerank-Read” 框架,在pipline的每个环节进行针对性优化:
检索前优化——弥合查询与文档间的语义鸿沟:
- 查询重写:让 LLM 改写、扩展用户原始查询,生成更适合检索的表述。
- HyDE:先让 LLM 生成一份”假设性回答文档”,再用该文档的嵌入向量去检索,显著提升了语义匹配精度。
- 查询分解:将一个复杂的多跳问题拆解为若干个原子子查询,分别检索后再聚合。
索引与分块优化——从根源减少信息损耗:
- **分块:**递归分块、父子分块(检索子块但返回父块以保留上下文)、元数据增强。
- 混合检索:将 BM25 等稀疏检索与向量密集检索并行使用,两者优势互补,成为当时的最佳实践。
检索后优化——提升信号纯度:
- 重排序:引入 Cross-Encoder 等神经重排模型,对初步检索结果进行二次精排。
- 上下文压缩:去除检索片段中的冗余信息,只保留与查询最相关的核心段落。
Advanced RAG 的本质是“修补”——它没有改变线性pipline的基本架构,而是在每个节点上做到了更精细的工程优化。
Advanced RAG → Modular RAG:从pipline到乐高积木
2024 年,学术界正式提出了 Modular RAG 的概念,核心思想是将 RAG 系统分解为独立的、可互换的功能模块,像乐高积木一样自由组合
这一范式定义了六大核心模块:
| 模块 | 职责 | 关键能力 |
|---|---|---|
| Indexing | 文档索引 | 多粒度分块、多模态嵌入 |
| Pre-Retrieval | 检索前处理 | 查询重写、HyDE、路由分发 |
| Retrieval | 检索执行 | 向量搜索、关键词搜索、知识图谱 |
| Post-Retrieval | 检索后处理 | 重排序、过滤、多路融合 |
| Generation | 内容生成 | Prompt 构造、输出格式控制 |
| Orchestration | 流程编排 | 线性/分支/循环/条件流程 |
Modular RAG 引入的**路由(Routing)**机制尤为关键——系统可以根据查询类型,动态选择不同的检索路径(例如事实查询走向量搜索,精确查询走关键词匹配,分析查询走知识图谱)。这标志着 RAG 从”固定Pipline”向”可编程系统”的质变。
GraphRAG:知识图谱检索的代表性突破
在 Modular RAG 的检索模块中,微软于 2024 年发布的 GraphRAG 是一个里程碑式的创新。它针对性地解决了纯向量检索在多跳推理和全局摘要上的结构性短板。
GraphRAG 的核心思想是:在索引阶段,先用 LLM 从文档中抽取实体和关系,构建知识图谱,再基于图结构进行社区检测和层级摘要。检索时提供两种模式:
- **Local Search:**沿图谱关系进行多跳遍历,精准回答具体问题
- **Global Search:**利用预生成的社区摘要,回答需要全局视角的概括性问题
GraphRAG 与向量检索并非替代关系,而是互补——向量检索擅长语义匹配,GraphRAG 擅长结构化推理。它们在 Modular RAG 框架下可以作为不同检索模块灵活组合,各展所长。
Modular RAG → Agentic RAG:LLM 成为决策者
演进的最后一步也是最关键的一步:将 LLM 从被动的”生成器”提升为主动的”编排者”。Agentic RAG 让大模型具备了自主决策检索策略的能力,具有四大核心特征:
- LLM 作为编排者:模型自主判断”是否需要检索""从哪里检索""用什么策略”,而不是机械地执行固定流程。
- 多步检索规划:面对复杂问题,Agent 会规划出一个包含多步检索和推理的执行计划,逐步逼近答案。
- 工具使用:检索手段不再局限于向量数据库,而是扩展到 SQL 查询、Web 搜索、API 调用、代码执行等任意工具。
- 自我反思与修正:Agent 会评估中间结果的质量,若不满意则自动回环——重新构造查询、切换检索策略、甚至尝试不同的工具组合。
这是一次本质性的跃迁:检索从”被动触发的固定动作”变成了”由智能体自主规划的动态行为”。
上下文工程:RAG 融入的更宏大框架
当 RAG 演进到 Agentic 阶段,一个更高维度的概念自然浮现——上下文工程(Context Engineering)。
2025 年,Shopify CEO Tobi Lütke 发表了一条引发广泛讨论的推文:
I really like the term “context engineering” over prompt engineering. It describes the core skill better: the art of providing all the context for the task to be done by the LLM.
前 OpenAI 研究员 Andrej Karpathy 随即响应:
+1 for “context engineering” over “prompt engineering”. People tend to think of “prompt” as the text you type into the chat box, but the “context” is so much more than that.
上下文工程的核心问题不再是”怎么写 prompt”或”怎么做检索”,而是:在模型推理的每一步,它应该”看到”什么信息? 这包括但远不限于检索结果:
| 上下文层 | 内容 | 来源 |
|---|---|---|
| System Instructions | 角色定义、行为约束、输出格式 | 开发者预设 |
| Long-Term Memory | 用户偏好、历史决策、知识积累 | 持久化存储 |
| Retrieved Documents | 外部知识、实时数据 | RAG 检索 |
| Tool Results | 函数调用返回、API 响应 | 工具执行 |
| Conversation History | 近期对话上下文 | 会话管理 |
| Current Task | 用户当前请求与约束 | 实时输入 |
Anthropic 在其工程博客中将这一理念系统化,提出了几个关键原则:
- 注意力预算:上下文窗口是有限资源,边际收益递减。好的上下文工程 = 找到最小的高信噪比 token 集合。
- Just-in-Time 上下文:不要预加载所有可能相关的信息,而是让 Agent 在运行时按需动态获取(Claude Code 的核心策略)。
- 上下文压缩与笔记:对于长任务,通过对话压缩(Compaction)和结构化笔记(Structured Note-Taking)来管理不断膨胀的上下文。
至此,RAG 的演进图景清晰地呈现出来:
| 范式 | 核心问题 | 关键特征 |
|---|---|---|
| Prompt Engineering | ”怎么措辞指令?“ | 手工编写 Prompt |
| Naive RAG | ”怎么找到相关文档?“ | 固定Pipline、向量检索 |
| Advanced RAG | ”怎么找得更准?“ | 查询优化、重排序 |
| Modular RAG | ”怎么灵活组合检索策略?“ | 模块化、路由、GraphRAG |
| Agentic RAG | ”怎么让模型自己决定检索策略?“ | Agent 驱动、自主规划、工具使用 |
| Context Engineering | ”模型在每一步应该看到什么?“ | 全局上下文管理、多源信息融合 |
RAG 没有消亡——它演进为 Agentic RAG,并作为核心检索层融入了 Context Engineering 的宏大框架。 就像”数据库”不会因为”数据工程”的出现而消亡一样,RAG 只是从一个独立的技术方案,变成了更大系统中不可或缺的基础组件。
顶级产品如何实践新一代RAG
理论的演进最终要由实践来检验。全球顶尖的 AI 产品非但没有抛弃 RAG,反而投入巨大的工程资源,将其升级为更强大、更智能的形态。
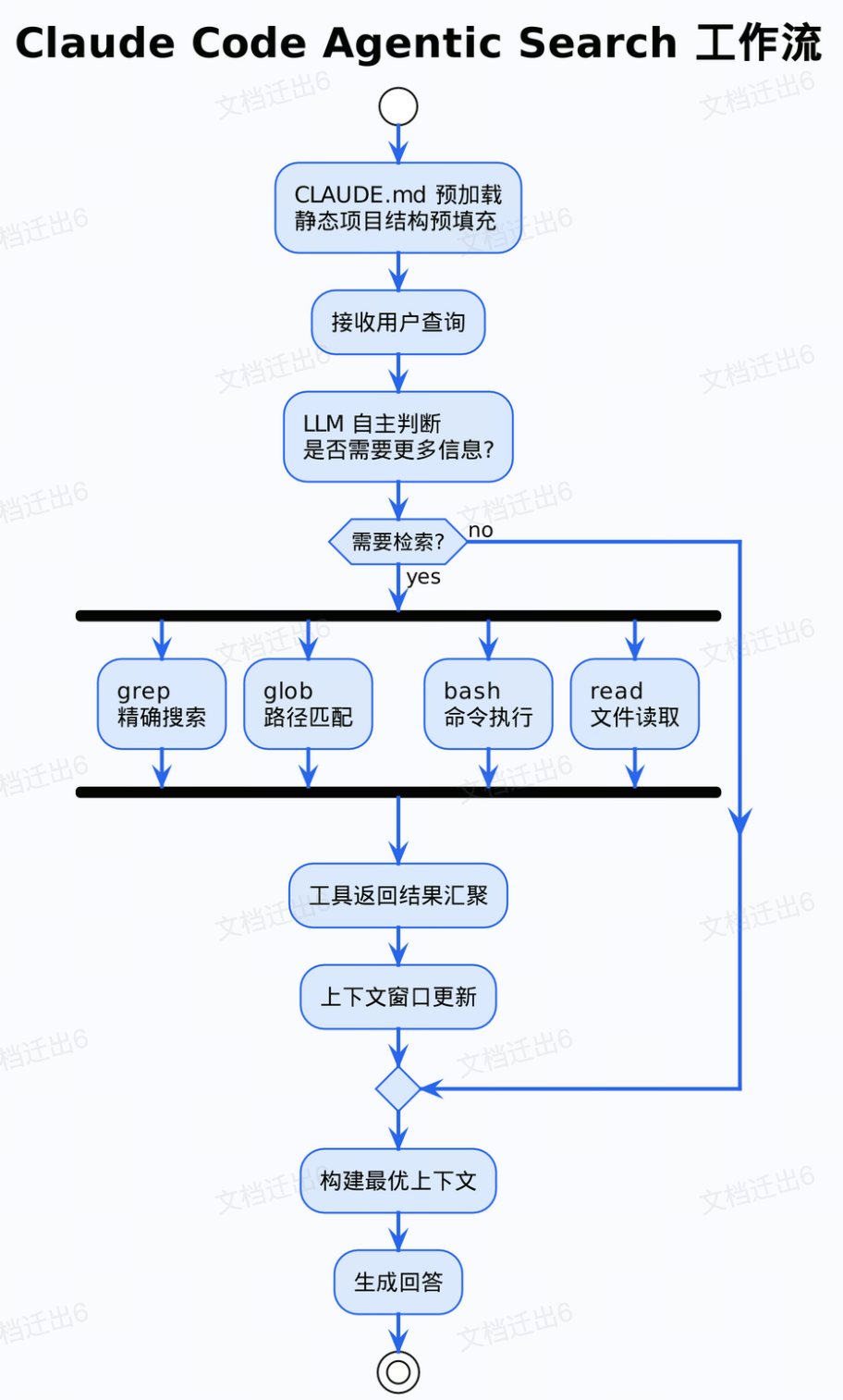
Claude Code:以 LLM 为检索引擎的动态 RAG
Anthropic 于 2025 年推出的 Claude Code,是 Agentic Search 范式最纯粹的代表。它在发布后 5 天内就达到了公司内部 50% 工程师的使用率,其核心在于一套“just-in-time context”(即时上下文)的检索策略。
Claude Code 完全抛弃了传统的向量数据库,转而赋予模型一个包含 grep、glob、bash 等 18 个工具的工具箱。在解决复杂编程任务时,模型会自主规划一个包含探索、复现、定位、修复、验证的多阶段计划,在长达百轮的工具调用中,按需、精准地从代码库中检索所需信息。
暂时无法在飞书文档外展示此内容
这套机制的本质,正是“以 LLM 为检索引擎的动态 RAG” 。检索引擎从外部的向量数据库,变成了 LLM 自身驱动的工具链;检索策略从静态的 k-NN 搜索,变成了由模型自主规划的多步信息采集。
Cursor:深度定制化的代码 RAG 系统
如果说 Claude Code 代表了“无向量索引”的 Agentic RAG 路径,那么 AI 编程环境 Cursor 则展示了“深度定制化 RAG 与 Agentic 能力融合”的极致。Cursor 的成功,建立在一套专为代码场景从头打造的 RAG 系统之上:
- AST语法分块:利用 tree-sitter 对代码进行抽象语法树解析,确保分块边界与函数、类等语义单元严格对齐,从根源上解决了传统分块的语义割裂问题。
- 自研 Embedding 模型:利用 Agent 真实工作轨迹数据进行训练,其代码语义搜索准确率相比通用模型提升了 12.5% 。
- Merkle Tree 增量同步:借鉴 Git 的 Merkle Tree 思想,实现了代码变更的毫秒级增量索引,将大型代码库的首次索引时间从 4 小时缩短至惊人的 21 秒 。每10分钟检查到哈希值不匹配,识别变化会只上传更新文件,减少带宽的消耗
- 混合检索架构:融合了语义搜索、精确关键词匹配和探索性子 Agent,以应对不同类型的查询需求。
Cursor 的实践雄辩地证明,对于专业领域,通过深度工程优化,RAG 系统能够达到的性能和效率远非“将代码塞入长上下文”可比。
Perplexity:支撑百亿美金估值的 RAG 管道
作为 RAG 商业化最成功的案例之一,Perplexity AI 的百亿美金级别估值本身就是对“RAG 已死”论调的有力反驳。
其核心竞争力,是一套每月处理超过 4 亿次搜索请求的、精心设计的五阶段 RAG Pipline:
- 混合检索:并行使用稀疏检索(如 BM25)和密集检索(向量搜索),优势互补。
- 候选筛选:快速过滤掉大量低质量和无关的初步结果。
- 神经重排:使用专门训练的 Reranker 模型,对候选文档进行精准排序。
- 上下文融合:将来自不同来源的检索结果,智能地融合成结构化的上下文。
- 多模型编排:根据查询的类型和意图,动态选择最合适的生成模型来给出答案。
从 OpenAI 的 Deep Research 项目到 Google 的 NotebookLM,我们都能看到类似的趋势:无论是采用纯粹的 Agentic RAG 架构,还是将超长上下文与 Agent 检索能力结合,检索始终是系统不可或缺的一环 。这些一线产品的选择,共同指向了同一个结论:RAG 不仅活着,而且活得更好。
结论:RAG is dead, long live RAG!
检索不会消亡,因为它解决了大型模型单靠参数化记忆永远无法解决的根本问题——企业级知识的动态性、规模性、精确性和私密性。真正消亡的,只是 Naive RAG 那种粗糙、脆弱的早期实现。
从 Naive RAG 到 Advanced RAG,再到 Modular RAG 和今天的 Agentic RAG,这是一条清晰的技术演进路径。每一步的进化,都是为了解决前一步的根本局限。这绝非新瓶装旧酒,而是深刻的范式革命。
RAG 并没有死,只是“隐形”了,已经内化成各种 AI 产品的基础组件---就像没人会特意强调“这个软件用到了数据库””一样。
只要模型推理与外部知识之间存在解耦需求,RAG就是你绕不过去的基本功!
额外的参考资料
- Building Effective Agents - Anthropic - https://www.anthropic.com/research/building-effective-agents
- How Claude Code is Built - The Pragmatic Engineer - https://newsletter.pragmaticengineer.com/p/how-claude-code-is-built
- From RAG to Context: 2025 Review - RAGFlow - https://ragflow.io/blog/rag-review-2025-from-rag-to-context
- Effective Context Engineering - Anthropic - https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Agentic RAG Survey - arXiv:2501.09136 - https://arxiv.org/abs/2501.09136
- RAG vs Large Context Window - Redis - https://redis.io/blog/rag-vs-large-context-window-ai-apps/