设想现在有一个 Agent,要在飞书视频会议 (VC) 的系统里完成一个跨服务的需求 —— 比如会议室预约流程里,某个状态变更需要同时通知 A 领域后端、触发 B 领域的推送、更新日程并通知前端。这个需求不复杂,但它牵涉三个团队、至少四个仓库、若干 PSM 边界。
🤔 Agent 该怎么开始?
对新项目或简单链路,很好回答:给一份需求文档,它能在干净的上下文里搭出骨架,跑通 demo,完成任务。但 VC 的系统不是新项目。它有多年的历史积累,有大量没有被文档化的约束,有散落在各个仓库里的实现细节,有只有老工程师才知道的边界条件。
“给文档、让 Agent 读、再去改代码”的直觉,针对新的独立项目已经足够。在业务里挑一个开发和测试能闭环的链路,让 AI 完全自主实现,也不再有挑战。但问题一旦扩大为在成熟系统里稳定自主地迭代功能,结构性的阻力就会出现,ToB 项目则更甚。
我们在组织 VC 的标准 Knowledge 仓库,这个仓库就是为这个场景设计的 Harness:一个面向商业化成熟系统、支撑军团规模工程协作的 Agent 工作现场。
**一、**阻力的真实来源
商业化成熟系统和新项目的本质关键差异,是上下文的分布方式,跟规模关系不大。
新项目的上下文是集中的:需求在文档里,规则在设计稿里,代码是从零开始的。Agent 只需要读懂文档,就能开始工作。
成熟系统的上下文是散的:设计文档可能已经过时,真实的约束藏在三年前的某次事故修复里,接口的边界条件只有看测试用例才能搞清楚,某个字段的含义需要同时对照三个服务的实现才能确认。这些上下文不在任何一个地方,它分散在代码、提交历史、测试用例、线上配置里。
更深的问题在于,相当一部分上下文根本无法被文档化。知识管理领域把这类知识称为隐性知识(Tacit Knowledge)——哲学家 Michael Polanyi 在 1966 年提出这个概念时,用了一句话来定义它:“我们能知道的,永远比我们能说出来的要多。” 骑自行车的人知道怎么保持平衡,但无法用语言把这个过程完整描述出来;老工程师知道这个接口在高并发下会有问题,但这个判断来自多年的直觉积累,从来没有被写进任何文档。
软件系统里的隐性知识尤其顽固且庞大。某个字段为什么不能为空,某个模块为什么不能被并发调用,某个服务为什么在特定时间窗口里会有性能抖动——这些约束可能从来没有被显式记录,它们以潜知识的形式,分散在团队成员的经验里。Spec-Driven Development 领域有一个经典的观察:文档会漂移,设计图会腐烂(“Requirements documents exist, but they drift。 Design diagrams are drawn, but they rot.”) . 在一个运行多年的商业化系统里,文档和代码之间的偏差是常态,不是例外。
在这种场景下,Agent 的问题根源是路径缺失。它找不到这个服务的规范入口,搞不清这个接口的真实约束在文档里还是测试用例里,不知道改完之后往哪里提交、跨仓变更怎么协调。路径不清晰,它就开始猜。猜错了就脑裂,随后乱改,是 AI Coding 过程中发生质量断崖式下降的原因。
提升模型能力解决不了这个问题。路径缺失是工作现场的设计问题,只能靠设计工作现场来解决。
也就是所谓的 Environment Engineering
二、Harness 是什么
在 AI 工程领域,Harness 有一个被广泛接受的定义:Agent = Model + Harness。
模型负责推理,Harness 负责其他一切——工具访问、上下文管理、执行环境、反馈回路、约束边界。Mitchell Hashimoto 把 Harness Engineering 描述为”每当 Agent 犯一个错误,就把这个错误变成系统约束,确保它不再犯第二次”。Martin Fowler 则把它拆成两层:模型厂商提供的内层 Harness,以及工程团队为自己的系统构建的外层 Harness。
外层 Harness
外层 Harness 才是真正因团队而异、因系统而异的部分。它要回答的是:这个 Agent 在我们的系统里,能不能把活干好。
对于上下文集中的新项目,这个问题相对容易回答,Agent 有了工具和权限基本就能跑起来。但在一个有多年历史的商业化系统里,外层 Harness 的设计难度会陡增。规则是隐性的,仓库是多个的,团队是分散的。Agent 需要一个能把这些散落上下文组织起来的工作现场 —— 知道从哪里进入,往哪里交付。
这正是我们设计这个仓库的出发点。它的定位是 VC 工程协作的外层 Harness,具体来说是 SPEC 层的 Harness:负责把规则、代码、交付路径组织成 Agent 可以直接使用的结构。
主要组成
一个合格的 SPEC 层 Harness 至少要回答三件事:去哪里找规则,去哪里找代码,如何交付结果。缺一不可。
规则和交付不用多说,“去哪里找代码”是最容易被忽视的,也是在成熟系统里最关键的。代码本身就是 SPEC 的一部分。 在商业化系统里,大量真实约束从来没有被文档化,它们活在代码里、测试用例里、某次线上事故之后加的那个 guard 里。
直白说,如果把代码和 SPEC 切开,Agent 读完文档之后无法马上知道相关代码约束的存在,就可能触发一个从来没有被文档化的边界条件。这种概率直接与 Agent 的性能挂钩,而这个判断直接决定了 Harness 的组织方式。
三、两种范式的选型
当下使用 Monorepo 有天然限制,实践中,Harness 项目有两种常见的接入模式,我将其称之为 Mainline 和 Distributed。
它们的差异,本质上是对”规则在哪里”这个问题的不同回答。
Mainline - 主线模式
Mainline 的假设是:规则在文档里,代码是规则的实现。做法是先提供一个统一的主干说明入口——global-spec、PSM 说明、模块关系图——把术语和边界先组织起来,代码仓后续再接入。这个思路和 Spec-Driven Development 的理想模型一致:规范声明意图,代码负责实现。
这个模式在规范推广的早期阶段有价值:门槛低,推进快,容易先在团队内部形成共识。但它有一个结构性的天花板:主干 SPEC 只能服务于理解,不能服务于编码。Agent 读完 global-spec 之后,仍然不知道代码在哪、改动在哪提交。如果代码仓没有接入,Mainline 就是一个只有导航、没有工作现场的模型。
所以 Mainline 有一条硬约束:一旦任务目标包含代码修改,必须先把对应代码仓接入 Harness,否则不能开始编码。
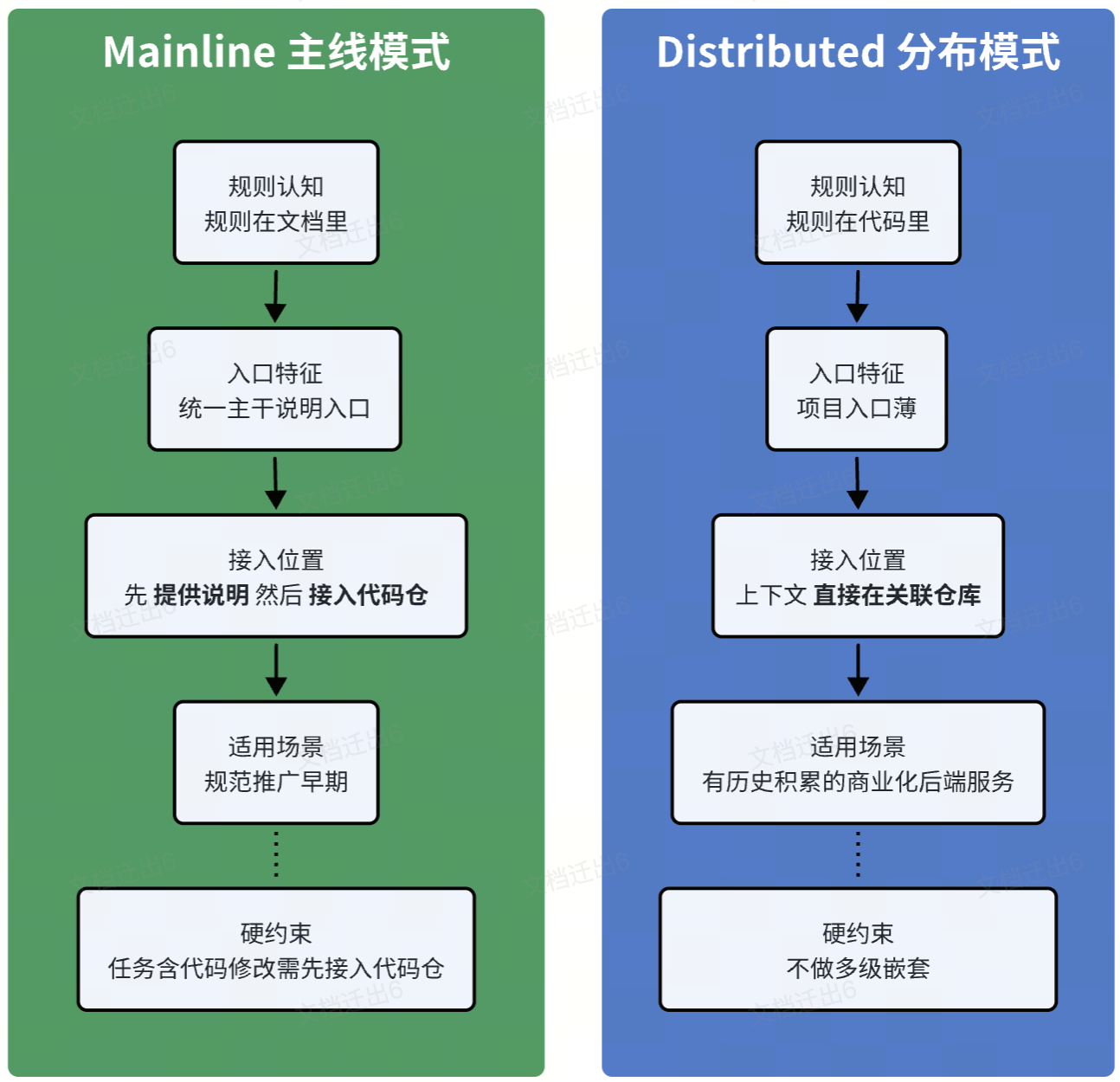
Distributed - 分布模式
Distributed 的出发点相反:承认规则大量沉淀在代码里,所以项目入口可以很薄,真实上下文分散在关联仓库里。Agent 顺着入口文件找到代码仓,直接在代码里读规则、改实现、提交结果。
这个模式更接近商业化系统的真实工作方式。
AI 工具领域有一个观察:当 Agent 能同时看到认证服务、API 网关和三个客户端实现,它对跨服务依赖的理解会发生质变——这和人类工程师需要在五个仓库之间来回切换是完全不同的工作方式。distributed 正是在利用这个优势:把代码直接纳入工作现场,让 Agent 能在同一个上下文里完成跨仓推理。
但它有自己的风险:如果不加约束,很容易往下嵌套层级,尤其当前 git 当前的管理模式还是面向于人,还没有生长出面向于 agent 的知识组织方式,我们只能依赖 submodule 做管理,最后谁也搞不清当前工作树的真实边界。Agent 在不同团队之间切换时,会遇到开发模式不一致的问题,维护成本会迅速失控。
所以 Distributed 也有一条硬约束:不做多级嵌套 (即 submodule 只有一层)。需要把代码仓带进来,统一挂在根目录一级,再由项目入口文件说明映射关系。
对于有历史积累的商业化后端服务,规则大量沉淀在代码里,distributed 通常是更合适的选择。mainline 更适合规范刚起步、或者团队内部文档体系已经相对完整的场景。
四、协议的最小集合
协议层和内容层要分开。内容层——模块怎么拆、术语怎么写、案例怎么归档——团队可以自由决定,Agent 在稳定的协议上自己能补全不完整的内容。协议层只有一条:入口文件必须让 Agent 知道三件事——当前项目是 Distributed 还是 Mainline,SPEC 从哪里进入,代码从哪里进入。
btw,这里还有有一个反直觉的判断:一个残缺但稳定的协议,比一个完整但会变的协议更有用。
协议的价值不在于完备性,在于可预期性。Agent 可以在稳定的起步路径上建立预期,遇到内容缺失时自己下钻;但如果协议本身在变,它每次进来都要重新定向,摩擦会持续存在。这也是为什么协议要尽量薄——薄的协议更容易保持稳定,团队也更容易接受。
举例来说
❌ 不合格的入口:这里放的是 admin 相关内容,后面再补一些项目说明。
👌🏻 合格的入口:本目录采用
distributed模式。SPEC 主入口见./index_admin.md,真实代码上下文来自根目录一级 submodulerepo-a与repo-b。若任务包含代码修改,必须同时阅读对应仓库中的实现与测试入口。
前者是「占位符」,后者是「协议」。
而协议的要义在于约束,Agent 读完,就能正确走出下一步,且在此前提下保持精简。
五、演进过程,结构的现状与走向
具体的结构设计和理由
Team Spec
最值得关注的现象是,当前我们把 spec 放在 teams_spec/,这显然还不够 AI Friendly,但是有意的:按团队划分,是最理想的过渡结构。
康威定律说:系统的架构,终将镜像设计它的组织的沟通结构。
这个规律在 AI 时代变得更加显著,我认为承认并克服这一点是面向成熟系统构建 Harness 的关键 —— 既然 Agent 不会绕过组织边界,它就会直接继承这些边界带来的摩擦。按团队划分的目录,意味着 Agent 处理跨团队任务时,必须先完成一次”组织架构到业务域”的映射才能找到正确入口。这个映射对人类工程师是隐性自动的,对 Agent 是额外的认知负担。
但我们不能为了让 Harness 更 AI Friendly 就去调整团队的组织结构。真正的解法是:在 Harness 里建一个和组织结构解耦的索引层,主动对抗康威定律在 AI 协作里的负面效应。
目录结构不必镜像组织架构,道理上来说应该镜像 Agent 的任务边界。这两件事在人类工程师那里是重叠的,在 Agent 这里可以分开。
从这个角度来说,Harness 本质上是一个渐进式加载的 monorepo —— 所有核心仓库都在这里,Agent 按需加载,在同一个工作现场里完成跨仓推理和提交,感知不到团队边界的存在。按业务域划分的索引层,是让这个 monorepo 对 Agent 可导航的关键。一个业务域的入口,应该能直接告诉 Agent:这个域涉及哪些服务,核心 PSM 边界在哪里,跨域协作的接口在哪里。从终局来看,这不仅仅是换一种分类方式,而是符合 Agent 管理一个项目的基本诉求。
从当前结构演进到这个终局,不需要一次性重构。路径是:先把协议跑通,再逐步把高频跨团队的业务域抽出来建独立入口,最终形成业务域优先的索引层。同时坚持底线:不要在当前的团队目录上继续加深层级,否则演进成本会越来越高,终局会越来越远。
所以我们应该要求所有工程师和 Agent 工作在这同一套机制上。
Skills 和 Knowledge 的边界
同时,当前设计了 Knowledge 和 Skill
Knowledge 也就是负责可复用经验的收集,面向 Harness 的成长。
Skills 则负责流程化能力,也就是我们常说的,Harness 最终要被拆掉的那些部分。
所以两者要分开,且所有使用的人都应该意识到,他们具有清晰的职责边界,且完全不具备互相替代关系。同理,也不应被 Team Spec 的内容污染。
用这种方式讨论这个区别的人还不多,但相信很快会讨论。
暂时不定 Knowledge 组织方式
这种组织方式代表了另一个重要话题,即如何弱化并持续的防御”漂移”现象。但我们打算把这个问题的彻底解决放在下一阶段,当前只提供牵引性的设计,鼓励汇总。是因为这里可以做的事更多了,更加开放。
以其中最核心的一个问题为例:knowledge 的归属——是每个团队自己维护,还是统一汇总。
倾向于多级 Inbox 的管理方式,因为提供多级的渐进式披露,以及构建 “睡眠” 等流程,对于知识管理而言,都是有效的实践。但现在不框定这一规范,是因为想先了解各团队的现有实践,也想看看 Agent 在这样的系统下的做事效果到底如何,控制一下变量。
趣闻,26 过年间给龙虾定制了不少 Memory 机制,包含睡眠,评测和体感都远超市面。现在大家对这类玩法想必熟了。这里值得保持开放性,根因还是这在当下属于值得 Build 的部分,玩法还很多很新,没有标准答案。
就拿 Knowledge 自洁和演化来说,关键不在于建设整理机制——定时清理信息是执行层面的事,任何人都能做到。真正的难点在于门禁和评测的设计:什么样的内容值得沉淀,什么样的内容应该被淘汰,这个判断标准如果没有显式定义,知识库只会越来越重,而不会越来越准。这就需要以已经滚动起来的实践为依托了。
六、验收标准
实践是检验真理的唯一标准,判断 Harness 是否跑通,就看:一个 Agent 进来,能不能在不问人的情况下,找到规则、找到代码、完成任务、交付结果。
交付的结果应该是端到端的。
入口文件详不详细、目录结构漂不漂亮,都不是判断依据,我们就看 Agent 能不能把活干的正确且有品。
回到开头那个场景:会议室状态变更,需要同时通知 VCA、触发 VCC 推送、更新妙记日程。如果一个 Agent 进来,能顺着 Harness 的入口文件找到三个服务的代码仓、读懂各自的约束、完成跨仓修改并提交——这个 Harness 就是有效的。如果它在某一步卡住了、开始猜、或者需要人来指路,就说明那个入口文件还没写到位,要继续改。
这个标准还有另一层含义:Harness 对接入团队的要求必须足够低,才能真正推出去。 如果接入一个项目需要团队重写一整套知识体系,没有人会做。
所以我们倾向于设计这样一套系统:协议薄、内容自由、渐进接入,规范没有侵入。规则够简单,执行起来才能顺利。这对于要构建这样系统的人也会是经验:围绕成熟系统构建让 Agent 用的开心的 Harness,本质还是在解决人的问题。
七、结语
Harness 不是一次性设计
系统在演进,服务在拆分,团队在调整,新的仓库在接入。每一次这样的变化,都可能让某个入口文件的描述变得过时,让 Agent 重新陷入路径缺失的状态。
Mitchell Hashimoto 定义 Harness Engineering 的逻辑在这里同样适用:每当 Agent 在某个地方卡住,就把那个卡点变成一条新的约束或更新一个入口文件,确保它不再卡第二次。Harness 的质量,是在这种持续的摩擦-修复循环里积累出来的,不是一次设计好的。
所以我们之后会有二期设计,解决还没有讨论完的 Knowledge 边界和迭代问题