Agent 的工作原理
要理解”AI 友好”到底在说什么,得先明白 AI Coding Agent(Claude Code、Cursor、Copilot 等)到底在怎么工作。它的工作循环大致是:搜索代码库 → 读取文件 → 理解上下文 → 生成代码 → 验证结果 → 循环。
每一步都有资源和注意力层面的硬约束:
| 步骤 | 约束 | 卡点 |
|---|---|---|
| 搜索代码库 | 每次搜索的 grep、ls 等操作都是一次工具调用 | 时间和调用次数有限 |
| 读取文件 | 每读一个文件都消耗 token | context window 有上限 |
| 理解上下文 | 超过 context window > 40% 后质量下降 | 注意力是稀缺资源 |
| 生成代码 | 依赖已理解的上下文 | 理解不够导致生成的代码有错 |
| 验证 | 需要能跑测试 / 编译 | 需要可执行的反馈回路 |
所谓”AI 友好”,说到底就是让 AI 能更简单、清晰地理解仓库内容,更轻量、准确地执行任务——在上面每一步都尽量减少调用、减少注意力占用,最终把准确率推上去。
业界已经出现了一批标准和协议尝试回答这个问题,下面是几个绕不开的:
AGENTS.md(https://agents.md/)
OpenAI Codex 团队发起,2025.12 捐赠给 Linux Foundation 的 Agentic AI Foundation (AAIF)。标准 Markdown 格式,告诉 AI Agent 项目的构建命令、测试指令、代码风格、安全注意事项。超过 6 万个开源项目已采用,Codex / Cursor / Copilot / Gemini CLI 等 20+ 工具原生支持。
llms.txt(https://llmstxt.org/)
Jeremy Howard(fast.ai)2024 年 9 月提出,最初主要面向网站,放在根路径 /llms.txt,用来存放给 AI 读取的仓库目录、文档索引等内容,让 AI 快速理解项目全貌。Anthropic、Zapier 等 2000+ 网站已实现,Docusaurus / VitePress 有官方插件支持。
Anthropic 2024.11 开源,2025.12 捐赠给 AAIF,Google、Microsoft、AWS、OpenAI 联合支持。JSON-RPC 2.0 协议,让 AI Agent 通过标准接口访问数据库、API、文件系统等外部工具。解决”每个 AI 工具都要写自定义集成”的问题。
Google 16-Factor App(https://cloud.google.com/transform/from-the-twelve-to-sixteen-factor-app)
Google Cloud 2025.10 发布,在经典 12-Factor 基础上新增 4 个 AI 因子:
- Prompts as Code:Prompt 纳入版本管理,与代码同等对待
- State as a Service:AI 应用状态外部化为服务
- Observability for Non-determinism:为非确定性输出建立可观测体系
- Trust & Safety by Design:安全信任从设计阶段内建
SDD——Spec-Driven Development(https://github.blog/ai-and-ml/generative-ai/spec-driven-development-with-ai-get-started-with-a-new-open-source-toolkit/)
GitHub 的 Spec-Driven Development 工具链,四阶段工作流:Constitution → Specify → Plan → Tasks → Implement。核心理念:Spec 越清晰结构化,AI 生成的代码质量越高。三层级:Spec-First(先写 Spec)→ Spec-Anchored(Spec 锚定实现)→ Spec-as-Source(Spec 即源码)。
DORA AI Capabilities Model(https://dora.dev/ai/)
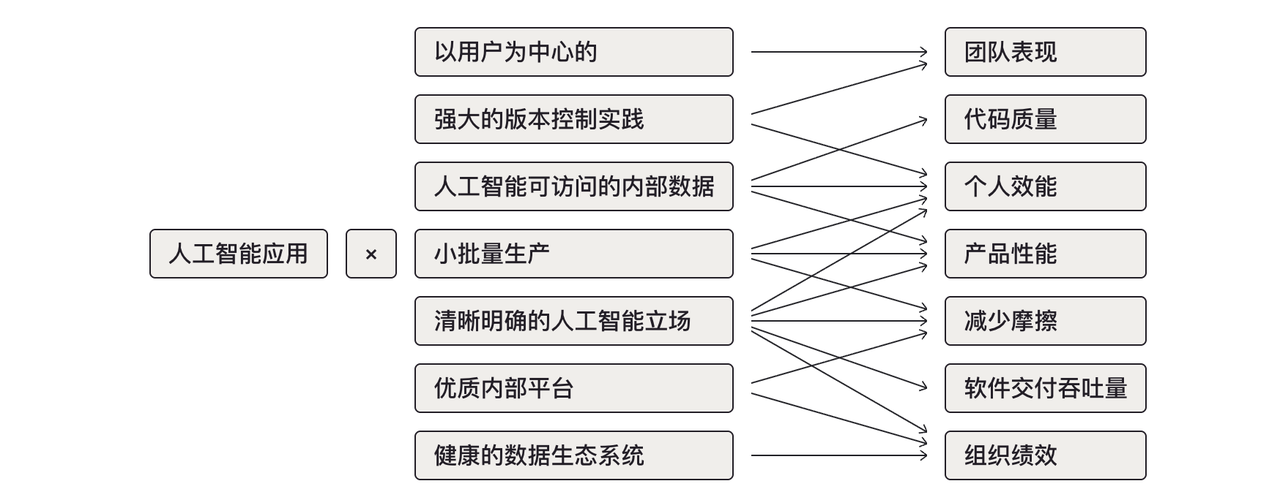
Google DORA 团队 2025 年发布,定义了 7 项 AI 基础能力(健康数据生态、明确 AI 策略、以用户为中心等)。关键发现:90% 组织已在用 AI,但成功更依赖文化与能力而非工具本身。把 AI 友好度的讨论从代码仓库扩展到了组织层级。
AI 友好三层架构
第一层:注解型架构
注解型架构的核心是把人类的设计意图、约束和领域知识以结构化方式落进代码仓库,让 AI Agent 可以像新来的工程师一样快速接入项目、理解上下文,从而高效、可控地参与开发。
入口文件和仓库说明书:Agent 的骨架
入口文件是整个仓库给 AI 的“第一印象”,通常是根目录下的一个约定文件(如 AGENTS.md、CLAUDE.md等),AI Agent 首次进入项目时会自动加载这个文件,获取全局上下文。
入口文件应作为 全局索引,而不应包含过多信息,其需要引导 Agent 在这一步了解如何看、查、改这个仓库,同时导向更多的文档内容,将仓库的所有文档串联起来
仓库说明书则是包含了仓库的详细介绍,比如:架构设计、服务地图、约束规范、业务领域、仓库规格、服务说明书等内容。
wrapper/
├── AGENTS.md // 目录/地图
├── docs/
│ ├── architecture/ // 架构设计
│ ├── index/ // 服务地图
│ ├── domains/ // 业务领域
│ ├── rules/ // 规范约束
│ ├── specs/ // 仓库规格
│ ├── test/ // 测试流程
│ └── manual/ // 服务说明书设计要点:
| 要点 | 说明 |
|---|---|
| 简洁性 | 内容应该是声明式而非过程式,描述“应该怎样”和“不能怎样”,而非放个 SOP 在里面 |
| 持续维护 | Owner 应当作为最核心的文件维护,而不是和现在大多仓库的 README 一样,写完就被搁在一边 |
| 单一入口构建知识网络 | 放在根目录作为全局规则,子目录局部覆盖 |
| 约束优先于自由 | 优先收紧约束,可靠性为先 |
知识库:业务需求的核心解决方案
AI Agent 在通用编程任务上已经接近人类水平,但工程团队在实际使用时普遍踩到同一个坑:AI 生成的代码语法正确、逻辑合理、但完全不符合业务需求。原因不复杂——业务知识不在模型训练数据里,也不在仓库代码里。以头条为例,大多数服务历史悠久,业务知识以口口相传、散落在大小飞书文档的方式维护,Agent 几乎无法回答:
- 发文服务的链路是怎样的?
- 短剧的元数据有哪些?
- 中小视频的定义是什么?
- XX 仓库过往的这个 MR 导致了什么业务异常?
没有业务知识内容,Agent 就只能通过暴力阅读大量仓库内的代码来了解业务知识,且效果十分有限。
而业务知识库要解决的就是:把散落在各处的知识,变成结构化、可发现的工程资产。
业务知识库的本质其实是 AGENTS.md 等内容的变种,都是为了提供更多的高价值上下文,只不过属性不同,它是以结构化文档形式维护的项目特有领域知识集合,供 AI Agent 和人类开发者共同使用。一份好的知识库可以包含:业务架构、领域定义、业务规范、经验教训(反例库) 等内容。
业务知识库不是新概念,团队一直有 quickStart 和 业务文档。新的是交付对象变了:过去写给人看,现在还要写给 AI 看,未来知识库就是代码的一部分
设计要点:
| 要点 | 说明 |
|---|---|
| 渐近式加载 | AI 不需要一次性知道所有事情,只在需要时加载相关知识 |
| 多级知识库 | 可以考虑采用全局、领域、局部的三层架构,避免单个文件过大并保证按需加载 |
| 知识库即代码 | 知识库与代码需要一样严格的创建、审核、维护流程 |
| 消除歧义 | 用术语表统一命名,避免同一概念在不同文档中叫法不同 |
| 多业务同结构 | 仓库若设计多业务,多个业务间的结构保持统一和规范 |
| 知识跨域 | 若存在多仓复用,可以考虑将知识库存放在团队的统一大仓 |
SKILLS:Agent 的 SOP
SKILLS 是面向 AI Agent 的可复用工作流定义——比 prompt 更结构化、比插件更轻量的能力封装。它告诉 Agent:在什么场景下、按什么流程、用什么标准来完成一类特定任务。
OpenAI 团队在分享了他们用 Skills 维护 Agents SDK 的数据:使用 Skills 后,两个仓库在 3 个月内(2025.12 - 2026.02)合并了 457 个 MR,而此前 3 个月(2025.09 - 2025.11)为 316 个 MR,增长 44.6%,主要是将验证、发布准备、示例集成测试和 CR 等重复性的工程工作封装成 SKILLS。
一份 SKILL 一般包含2部分:
- 元数据(Frontmatter)
定义 Skill 的身份、触发条件和描述,必须包含 :
- name:skill 的唯一标识
- description:告诉 Agent 何时使用此 Skill
除了以上内容其他均可选,比如:compatibility(可以注明必须安装的cli)、metadata(元信息,作者,版本等)
---
name: go-crud-generator
description: >
当用户需要为 Go 微服务生成 CRUD API 时使用。
触发词:新增接口、生成 CRUD、create API、添加 handler
---- 工作流指令
这部分需要完成 SKILLS 工作流的描述,比如调用命令,执行流程,边界判断,输入输出规范等等内容,这部分也是自然语言编写
- 以下是一个创建 PPE 研发流程的 SKILLS 例子:
---
name: "deploy-ppe"
description: "快速部署 toutiao.diversity.wrapper 服务,部署到PPE,默认使用 RD 自测流程、当前分支、lane-diversity-ppe 集群。Invoke when user asks to create dev task or dev flow."
---
# 部署ppe
快速部署 toutiao.diversity.wrapper 服务。
## 基本概念
- **Bits 研发流程**:团队统一平台。包含开发任务和发布单。
- **开发任务**:Bits 研发流程中的一个概念,用于需求的开发和测试阶段。
- **RD 自测**:研发流程类型,不需要 QA 介入。
- **Meego**:任务跟踪平台,与开发任务关联。
## 使用前准备
确保已通过 bytedcli 登录:
```bash
NPM_CONFIG_REGISTRY=http://bnpm.byted.org npx -y @bytedance-dev/bytedcli@latest auth login
```
## 环境变量配置(通过 export)
所有环境变量**必须通过 export 命令设置**,不要修改本地配置文件:
```bash
export USER_EMAIL_PREFIX=your.email.prefix
export BITS_SPACE_ID=369617922306
export MEEGO_SPACE_KEY=5f883b96d935ff846f802ea7
```
## 用法
### 基本用法(使用所有默认值)
```
创建研发流程 / 部署ppe
```
### 指定参数
```
创建研发流程 / 部署ppe,分支:feat_xxx,环境:ppe_xxx,集群:lane-diversity-ppe,流程类型:RD自测,PSM:toutiao.diversity.wrapper
```
## 默认参数
| 参数 | 默认值 | 说明 |
| ----------------------- | ------------------------- | --------------------------------- |
| **USER_EMAIL_PREFIX** | 用户提供 | 用户邮箱前缀,必须通过 export 提供 |
| **BITS_SPACE_ID** | 369617922306 | Bits 空间 ID |
| **MEEGO_SPACE_KEY** | 5f883b96d935ff846f802ea7 | Meego 空间 Key |
| **分支** | 当前 git 分支 | 使用 `git branch --show-current` 获取 |
| **研发流程** | RD自测需求研发流程 | teamFlowId: 387605767682 |
| **集群** | lane-diversity-ppe | 虚拟集群名称 |
| **环境** | 用户提供(非必填) | 环境名称 |
| **PSM** | toutiao.diversity.wrapper | 服务标识 |
| **Meego** | 必填 | 该流程必须关联 Meego |
## 环境命名规则
当用户未指定 PPE 环境名称时,按照以下规则生成:
1. 如果分支以 `feat_` 开头:替换为 `ppe_`
- 示例:`feat_dsp_style` → `ppe_dsp_style`
2. 如果分支以 `fix_` 开头:替换为 `ppe_`
- 示例:`fix_bug_123` → `ppe_bug_123`
3. 其他情况:前缀加上 `ppe_`
- 示例:`my_feature` → `ppe_my_feature`
## 可用研发流程
| 流程名称 | teamFlowId | 说明 |
| ---------- | ------------ | ------------- |
| RD自测需求研发流程 | 387605767682 | 不需要 QA 介入(默认) |
| QA介入需求研发流程 | 389027880194 | 需要 QA 介入 |
| 无meego研发流程 | 404235990274 | 不需要关联 Meego |
## 可用集群
- lane-diversity-ppe(默认)
- lane-diversity-toutiao
- lane-diversity-sj
- lane-diversity-howy
- lane-diversity-mix
- lane-diversity-creator
## 创建前确认(必须执行)
在正式执行创建命令前,会以表格形式向用户确认:
| 配置项 | 值 |
| ------------- | ------------------------- |
| **分支** | [分支名] |
| **研发流程** | [流程名] |
| **项目** | toutiao.diversity.wrapper |
| **集群** | [集群名] |
| **环境** | [环境名] |
| **空间 ID** | 369617922306 |
| **Meego Key** | 5f883b96d935ff846f802ea7 |
请确认以上信息无误后,再继续执行。
## 环境变量设置(必须通过 export)
创建前必须先设置环境变量:
```bash
export USER_EMAIL_PREFIX=miaoqianrun.777
export BITS_SPACE_ID=369617922306
export MEEGO_SPACE_KEY=5f883b96d935ff846f802ea7
```
## 创建命令
使用的基准命令:
```bash
NPM_CONFIG_REGISTRY=http://bnpm.byted.org npx -y @mcp_hub/bits-devops bits_create_dev_task \
--teamFlowId <teamFlowId> \
--projectNames toutiao.diversity.wrapper \
--branch <branch> \
--laneId <ppeName> \
--title "<title>" \
--meegoUrl "<meegoUrl>"
```
## 参数说明
| 参数 | 说明 | 示例 |
| ---------------- | ------------ | ---------------------------------- |
| `--teamFlowId` | 研发流程模板 ID | `387605767682` |
| `--projectNames` | 项目名称 | `toutiao.diversity.wrapper` |
| `--branch` | Git 分支 | `feat_dsp_style_optional` |
| `--laneId` | 环境名称 | `ppe_wrapper_ai` |
| `--title` | 开发任务标题 | `toutiao.diversity.wrapper PPE 部署` |
| `--meegoUrl` | Meego 需求 URL | `https://meego.larkoffice.com/...` |
## 查看开发任务
创建成功后会返回开发任务链接,格式为:<https://bits.bytedance.net/devops/><spaceId>/develop/detail/<devtaskId>
开发任务信息示例:
- 开发任务 ID:2219331
- 开发任务链接:<https://bits.bytedance.net/devops/369617922306/develop/detail/2219331>
使用以下命令查看状态:
```bash
NPM_CONFIG_REGISTRY=http://bnpm.byted.org npx -y @mcp_hub/bits-devops bits_get_dev_task_basic_info --devtaskId <devtaskId>
```
## 示例
### 示例 1:使用默认参数创建
假设当前分支是 `feat_dsp_style_optional`,环境是 `ppe_wrapper_ai`:
```bash
export USER_EMAIL_PREFIX=miaoqianrun.777
export BITS_SPACE_ID=369617922306
export MEEGO_SPACE_KEY=5f883b96d935ff846f802ea7
NPM_CONFIG_REGISTRY=http://bnpm.byted.org npx -y @mcp_hub/bits-devops bits_create_dev_task \
--teamFlowId 387605767682 \
--projectNames toutiao.diversity.wrapper \
--branch feat_dsp_style_optional \
--laneId ppe_wrapper_ai \
--title "toutiao.diversity.wrapper 开发任务" \
--meegoUrl "https://meego.larkoffice.com/13/story/detail/6861807503"
```
### 示例 2:指定研发流程
使用 QA 介入流程,未指定环境名称:
```bash
export USER_EMAIL_PREFIX=miaoqianrun.777
export BITS_SPACE_ID=369617922306
export MEEGO_SPACE_KEY=5f883b96d935ff846f802ea7
NPM_CONFIG_REGISTRY=http://bnpm.byted.org npx -y @mcp_hub/bits-devops bits_create_dev_task \
--teamFlowId 389027880194 \
--projectNames toutiao.diversity.wrapper \
--branch feat_dsp_style_optional \
--title "toutiao.diversity.wrapper 开发任务" \
--meegoUrl "https://meego.larkoffice.com/13/story/detail/6861807503"
```
## 注意事项
1. 所有环境变量**必须通过 export 命令设置**,不要修改本地文件
2. 默认使用 RD 自测流程(teamFlowId: 387605767682)
3. 该流程必须关联 Meego,请确保提供有效的 Meego URL
4. 创建前必须执行"创建前确认(必须执行)"
5. 创建可能需要几秒钟,请耐心等待
6. 如果创建失败,检查环境变量是否正确设置当然 SKILLS 的设计并不那么局限,它其实就是一类可重入的 prompt,以下是 claude code 著名的 /batch 命令的实现,通过动态代码 init:
import { AGENT_TOOL_NAME } from '../../tools/AgentTool/constants.js'
import { ASK_USER_QUESTION_TOOL_NAME } from '../../tools/AskUserQuestionTool/prompt.js'
import { ENTER_PLAN_MODE_TOOL_NAME } from '../../tools/EnterPlanModeTool/constants.js'
import { EXIT_PLAN_MODE_TOOL_NAME } from '../../tools/ExitPlanModeTool/constants.js'
import { SKILL_TOOL_NAME } from '../../tools/SkillTool/constants.js'
import { getIsGit } from '../../utils/git.js'
import { registerBundledSkill } from '../bundledSkills.js'
const MIN_AGENTS = 5
const MAX_AGENTS = 30
const WORKER_INSTRUCTIONS = `After you finish implementing the change:
1. **Simplify** — Invoke the \`${SKILL_TOOL_NAME}\` tool with \`skill: "simplify"\` to review and clean up your changes.
2. **Run unit tests** — Run the project's test suite (check for package.json scripts, Makefile targets, or common commands like \`npm test\`, \`bun test\`, \`pytest\`, \`go test\`). If tests fail, fix them.
3. **Test end-to-end** — Follow the e2e test recipe from the coordinator's prompt (below). If the recipe says to skip e2e for this unit, skip it.
4. **Commit and push** — Commit all changes with a clear message, push the branch, and create a PR with \`gh pr create\`. Use a descriptive title. If \`gh\` is not available or the push fails, note it in your final message.
5. **Report** — End with a single line: \`PR: <url>\` so the coordinator can track it. If no PR was created, end with \`PR: none — <reason>\`.`
function buildPrompt(instruction: string): string {
return `# Batch: Parallel Work Orchestration
You are orchestrating a large, parallelizable change across this codebase.
## User Instruction
${instruction}
## Phase 1: Research and Plan (Plan Mode)
Call the \`${ENTER_PLAN_MODE_TOOL_NAME}\` tool now to enter plan mode, then:
1. **Understand the scope.** Launch one or more subagents (in the foreground — you need their results) to deeply research what this instruction touches. Find all the files, patterns, and call sites that need to change. Understand the existing conventions so the migration is consistent.
2. **Decompose into independent units.** Break the work into ${MIN_AGENTS}–${MAX_AGENTS} self-contained units. Each unit must:
- Be independently implementable in an isolated git worktree (no shared state with sibling units)
- Be mergeable on its own without depending on another unit's PR landing first
- Be roughly uniform in size (split large units, merge trivial ones)
Scale the count to the actual work: few files → closer to ${MIN_AGENTS}; hundreds of files → closer to ${MAX_AGENTS}. Prefer per-directory or per-module slicing over arbitrary file lists.
3. **Determine the e2e test recipe.** Figure out how a worker can verify its change actually works end-to-end — not just that unit tests pass. Look for:
- A \`claude-in-chrome\` skill or browser-automation tool (for UI changes: click through the affected flow, screenshot the result)
- A \`tmux\` or CLI-verifier skill (for CLI changes: launch the app interactively, exercise the changed behavior)
- A dev-server + curl pattern (for API changes: start the server, hit the affected endpoints)
- An existing e2e/integration test suite the worker can run
If you cannot find a concrete e2e path, use the \`${ASK_USER_QUESTION_TOOL_NAME}\` tool to ask the user how to verify this change end-to-end. Offer 2–3 specific options based on what you found (e.g., "Screenshot via chrome extension", "Run \`bun run dev\` and curl the endpoint", "No e2e — unit tests are sufficient"). Do not skip this — the workers cannot ask the user themselves.
Write the recipe as a short, concrete set of steps that a worker can execute autonomously. Include any setup (start a dev server, build first) and the exact command/interaction to verify.
4. **Write the plan.** In your plan file, include:
- A summary of what you found during research
- A numbered list of work units — for each: a short title, the list of files/directories it covers, and a one-line description of the change
- The e2e test recipe (or "skip e2e because …" if the user chose that)
- The exact worker instructions you will give each agent (the shared template)
5. Call \`${EXIT_PLAN_MODE_TOOL_NAME}\` to present the plan for approval.
## Phase 2: Spawn Workers (After Plan Approval)
Once the plan is approved, spawn one background agent per work unit using the \`${AGENT_TOOL_NAME}\` tool. **All agents must use \`isolation: "worktree"\` and \`run_in_background: true\`.** Launch them all in a single message block so they run in parallel.
For each agent, the prompt must be fully self-contained. Include:
- The overall goal (the user's instruction)
- This unit's specific task (title, file list, change description — copied verbatim from your plan)
- Any codebase conventions you discovered that the worker needs to follow
- The e2e test recipe from your plan (or "skip e2e because …")
- The worker instructions below, copied verbatim:
\`\`\`
${WORKER_INSTRUCTIONS}
\`\`\`
Use \`subagent_type: "general-purpose"\` unless a more specific agent type fits.
## Phase 3: Track Progress
After launching all workers, render an initial status table:
| # | Unit | Status | PR |
|---|------|--------|----|
| 1 | <title> | running | — |
| 2 | <title> | running | — |
As background-agent completion notifications arrive, parse the \`PR: <url>\` line from each agent's result and re-render the table with updated status (\`done\` / \`failed\`) and PR links. Keep a brief failure note for any agent that did not produce a PR.
When all agents have reported, render the final table and a one-line summary (e.g., "22/24 units landed as PRs").
`
}
const NOT_A_GIT_REPO_MESSAGE = `This is not a git repository. The \`/batch\` command requires a git repo because it spawns agents in isolated git worktrees and creates PRs from each. Initialize a repo first, or run this from inside an existing one.`
const MISSING_INSTRUCTION_MESSAGE = `Provide an instruction describing the batch change you want to make.
Examples:
/batch migrate from react to vue
/batch replace all uses of lodash with native equivalents
/batch add type annotations to all untyped function parameters`
export function registerBatchSkill(): void {
registerBundledSkill({
name: 'batch',
description:
'Research and plan a large-scale change, then execute it in parallel across 5–30 isolated worktree agents that each open a PR.',
whenToUse:
'Use when the user wants to make a sweeping, mechanical change across many files (migrations, refactors, bulk renames) that can be decomposed into independent parallel units.',
argumentHint: '<instruction>',
userInvocable: true,
disableModelInvocation: true,
async getPromptForCommand(args) {
const instruction = args.trim()
if (!instruction) {
return [{ type: 'text', text: MISSING_INSTRUCTION_MESSAGE }]
}
const isGit = await getIsGit()
if (!isGit) {
return [{ type: 'text', text: NOT_A_GIT_REPO_MESSAGE }]
}
return [{ type: 'text', text: buildPrompt(instruction) }]
},
})
}设计要点:
| 要点 | 说明 |
|---|---|
| 核心内容 description | description 应该遵循: - 场景优先:什么场景触发 - 触发词:关键的触发词 |
| 步骤验证 | 执行流程中补充检查点,避免全部执行完毕后再进行检查,浪费token |
| 输入输出规范 | 明确“输入”和“输出”要求,避免 Agent 自行脑补 |
| 单一职责 | 一个 SKILL 只做一件事,确有需要则可通过 SKILL 引用 SKILL 进行组合串联,甚至是 Agent 组合 |
| 容灾操作 | 明确失败后的处理方式,及时止损 |
SDD:规格驱动编码
SDD 即 Spec-Driven Development(规范驱动开发),在 Coding 前优先生成 Spec(规范),完成后再根据 Spec 进行代码生成。Spec 既是给人看的设计说明,也是给 AI 的可执行预案。
简单来说就是为 Agent 提供一套标准的业务开发流程,一般为:通过 PRD 等上下文 → 生成 Spec(执行预案)→ 代码生成。
Thoughtworks 在 2025 年底将 SDD 列为年度最重要的 AI 辅助工程实践之一,其核心观点是:规范不仅仅是产品需求文档(PRD),它必须显式定义目标软件的外部行为——输入输出映射、前置/后置条件、不变量、约束、接口类型。
根据 Thoughtworks 和社区实践总结,好的 Spec 应该满足:
| 标准 | 说明 | 反例 |
|---|---|---|
| 领域语言 | 使用业务的统一术语黑话,而非实现细节 | 把 type 字段从 1 改成 2 |
| 结构清晰 | 统一使用 Given/When/Then 或标准模板 | 自由散文叙述接口行为 |
| 完整而精炼 | 覆盖关键路径,不枚举所有边界 | 列出 50 种异常情况 |
| 确定性 | 字段类型、错误码、约束都是明确的 | 返回适当的错误信息 |
| 可机器解析 | 使用 Markdown 表格、代码块等结构化格式 | 纯自然语言描述表结构 |
引入 Spec 套件会带来额外维护成本:除了 review AI 生成的代码,还要 review 它产出的预案、任务等 markdown 文件。所以是不是每个需求都适合上 Spec 要区分场景——小需求、小 bug 修复硬上 Spec 反而适得其反。
SDD 本质上是一次范式转移:
当 AI 让写代码变得廉价时,设计和规格说明才是真正有价值的人类工作。SDD 把这个流程规范化了。
目前 Claude Code 等 Agent 支持 /plan mode 等 SKILLS,但其过程中产生的 spec 工作内容并不会落到磁盘,因此 Spec 目前主要通过 OpenSpec、Spec Kit 等工具接入:
- Spec 对比
| 对比维度 | Spec Kit | BMAD | OpenSpec | LeanSpec |
|---|---|---|---|---|
| 核心理念 | 重规则 用 constitution.md 作为项目基本法,所有 spec/plan/task 必须符合约束 | 内置多智能体 12+ 专业 Agent 角色(PM、Architect、Dev 等)分工协作,模拟完整软件团队,支持上下文分片 | 变更驱动迭代 以 “提案” 为原子单位,从 proposal → spec → design → tasks 渐进细化 | 目前最轻量的 SDD 框架,目标是在 Spec-Kit / OpenSpec 之上进一步降低规格成本。 |
| 工作流产物 | constitution.md → spec.md → plan.md → tasks/ 任务文件;产物存放在 .specify/memory/ | .bmad/ 配置目录 + docs/ 产物目录;产物包括 PRD、Architecture、Story、Task 等,按角色输出 | specs、changes、proposal,每个项目独立目录 | specs/ 目录下编号特性文件(如 001-auth.md),单文件即完整 spec,无复杂目录层级 |
| 操作简介 | /specify → /plan → /tasks,严格顺序执行,阶段不可跳跃 | npx bmad-method install 安装后,通过 Agent 角色切换触发(如 @pm、@architect、@dev),支持 Party Mode 全自动流水线 | /opsx:propose → /opsx:apply → /opsx:archive;另有 /opsx:status、/opsx:review 等 20+ 辅助命令 | 无显式命令;通过 MCP Server 协议自动响应 AI Agent 的读写请求,自然语言驱动 |
| 可审计性 | 中:通过 Markdown 任务列表追踪,无内置 diff/changelog | 高:每个角色产出有明确 checklist 和验收标准,支持 yolo 快速模式和严格审查模式切换 | 高:每个变更有独立目录和完整生命周期(proposal → archive),天然支持 Git diff,变更历史结构化 | 低:轻量设计,spec 文件本身即记录,依赖 Git 做版本管理,无内置审计机制 |
| 适用场景 | 全新项目启动 (Greenfield) 适合 0→1 | 中大型复杂项目;适合需要模拟完整团队协作的场景,但不适合 1→n | 增量开发 (Brownfield) 与持续迭代 (1→n),工具链兼容性最广(20+ 工具) | 个人 / 小型项目快速搭建 |
Harness:人类掌舵,智能体执行
2025年8月,OpenAI Codex 团队开始了一个内部实验:让几名工程师从 0 开始,建设并迭代一个没有任何手写代码的项目。结果是 5 个月后,累计了 1500 次 PR,100w行+ 的代码,且项目已经有了数百位内测用户。
2026 年初,OpenAI Codex 的 论文 使得“Harness Engineering” 作为一个独立学科正式进入业界视野:早期进展比我们所预期的要慢,而这并不是因为 Codex 不具备相应的能力,而是因为环境的规范不够明确。最早提出 Harness Engineering 概念的 Hashimoto 的 定义:每当发现某个智能体犯错时,就花时间设计一个解决方案,确保它以后不再犯同样的错误。
同时论文也直接指出了未来工程师的角色转换:软件工程团队的首要工作不再是写代码,而是设计系统、架构和杠杆作用。
Harness 直译 “马具”,Harness Engineering(驾驭工程)是 AI Agent 的执行环境和管控框架——定义了 AI Agent 能做什么、怎么做、做完怎么验证。
OpenAI 实验形成的一套 Harness 最佳实践:Agent 不难,难的是 Harness
| 观点 | 介绍 |
|---|---|
| 代码仓库优先 | Harness 所使用的定义、内容,都应该在仓库代码中,而非外部的知识 |
| 代码 AI 友好 | 代码不仅人看得懂,AI 也要看得懂 |
| 约束规范 linter、CI 化 | 自然语言描述的约束不够稳定,linter 才是真理 |
| 权限优先收紧 | 不要一开始就给 Agent 全部权限,要设置阶段和门禁 |
| 异常的归因 | 如果一个 PR 需要大量人工干预,问题不在 Agent,在 Harness |
除了 OpenAI 走大规模生产路线的验证,Anthropic 则走的是认知科学路线
Anthropic 团队的 Prithvi Rajasekaran 进行了几个月针对 高质量前端设计 和 无需人工干预即可构建完整程序的研究,最终形成了一套以 GAN 为理论基础,能在数小时内的自助编码中落地具有丰富功能应用的多智能体集群(规划器、生成器和评估器)
Anthropic 团队发现在没有 Harness 约束下的 Agent 往往存在这 4 个问题:
- 过度自信的模型:让 Agent 评价自己的工作时,它会 “自信地夸奖自己的作品,即使质量明显平庸”
- 上下文焦虑:Agent 在接近上下文窗口上限时会表现出“过早收工”倾向
- 宽以待己,严以律人:让生成者自我批评并找到问题往往比让一个评估者锐评困难得多
- 模型能力提升后,Harness 可以考虑做减法:随着 Opus 4.6 的发布,之前必要的 Sprint 分解机制(Spec 机制演化:由生成器提出,评估器确定提案正确性和结果验收)可以去掉了
Anthropic 实验形成的一套 Harness 最佳实践:Harness 的本质是为 LLM 的认知缺陷兜底
| 观点 | 介绍 |
|---|---|
| 任务状态传递 | 任务状态应该有独立的记录文件,不止仓库代码 |
| 一次只做一件事 | 每个会话只实现一个功能 |
| 模型本身无法可靠自评,需要外部评估 | 设计专门的评估器智能体 |
| 真实工具验证 | 通过 Playwright 端到端测试 |
| Harness 随模型能力而精简 | Harness 是一个动态系统,应该随模型能力外扩而持续精简 |
每个 Agent Harness,无论简单还是复杂,都基于相同的五个支柱构建。
- **工具编排:**定义 AI Agent 可以调用的工具和权限
- **护栏约束:**定义操作便捷,防止 Agent 执行有害操作,更多约束通常带来更高的可靠性,而非更低
- **错误恢复和反馈能力:**自动重试、自我验证、操作回滚等
- **可观测:**针对 Agent 的行为链路、token消耗、决策等内容进行记录,同时支持报警、回放等操作,方便 Agent 和使用者进行探测和复用
- **人机协作检查点:**预先设定的询问节点,如在执行高危操作、方案确定等时机
以上为 Harness 在 Agent 的落地,而对于仓库级的 Harness = 入口配置 + Skills/Commands 等工具流 + Hooks + CI + 环境/文件隔离,全部以文件形式存放在仓库中,随代码一起进行版本管理。
第二层:代码级架构
代码级架构关注代码本身的可读性和可维护性,目标是把 AI Agent 理解、修改代码的认知成本降到最低。当前 LLM 编码助手的硬约束是”上下文窗口有限 + 缺乏运行时状态感知”,架构层面的 AI 友好本质上在解决两件事:
- 减少 AI 任务需要的上下文
- 增加 AI 产出的确定性
垂直切片:Agent 眼中的轻量化仓库
传统设计模式下,仓库通常是 handler → service → loader → dal 这种分层结构,每层职责明确。
但 AI 的认知模型完全不同:
- 人类:脑中有全局架构图,改一个功能时知道先改 handler、再改 service、再改 dal,再改 model,一路往下
- AI:每次只看到有限的上下文窗口,过度的目录跳转就是在浪费注意力
**垂直切片(Vertical Slice)**并不是一个新话题,早在 2018 年Jimmy Bogard 就提到了相关的论点,只不过当时并不是 for Agent,而是一个代码架构的尝试:把一个功能的所有代码放在一起,改一个功能只动一个目录。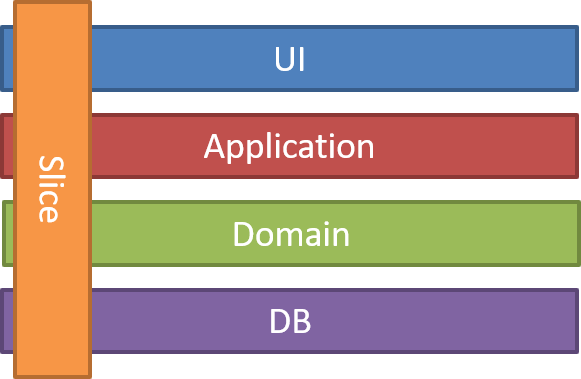
Anthropic 的 Claude Code 最佳实践文档处处提到:“减少文件读取和跳转次数”。比如可以将相关代码放在一起来最小化 AI 需要读取的文件数,因为每次文件读取都消耗 token 并增加出错概率。
垂直切片和 DDD 的区别在于 DDD 更加强调领域的复用,而非功能维度的目录隔离,而垂直切片拆分的 Slice 可以接受业务代码重复,也尽量保证隔离度。
但垂直切片和 DDD 实际并不冲突,对于业务领域内容可以按照 DDD 划分,功能级别按照垂直切片划分。
由于 AI 的上下文窗口是稀缺资源。以 Claude 为例,虽然支持 200K tokens,但实际编码场景中,AGENTS.md + SKILLS、对话历史、甚至还有你发给 Agent 的飞书文档等信息,留给代码阅读的空间往往不剩多少,更致命的是:AI 读大文件时可能被截断,丢失后半段关键信息,这也是 TRAE 读取超大文件 > 1000 行时的任务效果不佳的原因。
因此单文件大小也是核心问题之一:
- GitHub Copilot 的上下文引擎研究表明:代码补全准确率与单文件信息密度强相关。文件越长,相关代码在文件中占比越低,补全准确率呈对数衰减。
| 指标 | 最佳实践 | 极限 | token 参考 |
|---|---|---|---|
| 单文件 | 200-300 行 | 500 行 | ≈ 3K-4K tokens |
| 单函数 | 30-50 行 | 80 行 | ≈ 200-500 tokens |
| 单 struct | 8-10 字段 | 15 字段 | AI 完整赋值不遗漏 |
| 单 package | 5-7 文件 | 10 文件 | AI 扫描全包建立理解 |
**核心原则:**拆分的粒度应该是AI 完成一次修改需要读的最小文件集,过细会导致大量文件跳转,过大则是单文件挤满上下文。
架构统一:从有限视角推测全局
Anthropic 在最佳实践里明确说过一句话:Reference existing patterns. Point Claude to patterns in your codebase. 让 Agent 先看一个典型示例,再照着这个模式实现新功能,前提是仓库里的实际代码本身风格一致、架构一致。
架构统一不等于所有代码长一个样,而是同类问题用同一种模式解决,使 Agent 能通过模式匹配高效推理。落到实处就两点——结构统一、思路统一。
- 结构统一:统一的写法风格、目录规范、函数和文件的命名规范等
// Agent 可以直观理解目录下的 go 文件业务属性和功能
features/
├── ft_3rd
│ ├── f_ad
│ │ ├── TuwenLegacyAdExtraPL.go
│ │ ├── TuwenLegacyAdExtraPL_test.go
│ └── f_noval
│ ├── d_novel
│ │ ├── PL.go
│ │ ├── PL_test.go
├── ft_ai
│ ├── TagInfoPL.go
│ ├── f_ai_curated
│ │ ├── AICuratedPL.go
│ │ └── AICuratedPL_test.g
AI 是极强的模式模仿者。它在仓库中看到的代码风格就是它认为的正确风格。而大型仓库往往由较多同学一同维护,不好的写法很容易大量复制和分裂,最终污染整个仓库。
// 同学A:合理封装实验参数,多处复用
if params != nil && params.EnableProfileVideoImmerse() {
tab = constdef.MyTab_VideoImmerse
}
// 同学B:不封装实验参数,无法复用,大量重复代码
if musicThrottling := s.originReq.ServiceAbTestJson().Get("toutiao_lite").Get("music_anchor_throttling").MustInt(100); musicThrottling == 0 {
itemCell.GetVideoAbility().GetMixedStreamData().SetBottomBar(nil)
}大型仓库中,分层的架构需要保证:上层依赖下层,AI 生成代码也应当遵循这个要求,如果有特定的框架流程,可以搭建各类脚手架生成代码,AI 补充即可。
- 思路统一:相同的业务内容使用相同的设计模式
// logpb 使用 LogPbCtrl 进行赋值,而非散落在各个业务代码中
logPbCtrl := register.NewLogpbCtrl(ctx, rp.ReqParams, s.GetInteractor()).Biz(biz.Xsp).Build()// rpc 在 仓库统一封装为 fetcher,并且统一使用 airpass 而非 overpass
func MGetItemCounter(ctx context.Context, itemIDs []int64) *requtil.Fetcher[int64, *d_stat.ItemCounter] {
return requtil.NewFetcher(ctx, nil, itemIDs, func(keys []int64) map[int64]*d_stat.ItemCounter {
return callMGetItemCounter(ctx, keys)
})
}Monorepo:应对跨场景任务
Propel 的研究指出:现代 AI 模型 128K-1M 的上下文窗口其实是利好 monorepo 的——AI 可以在单一上下文里追踪原本需要跨微服务的数据流转。
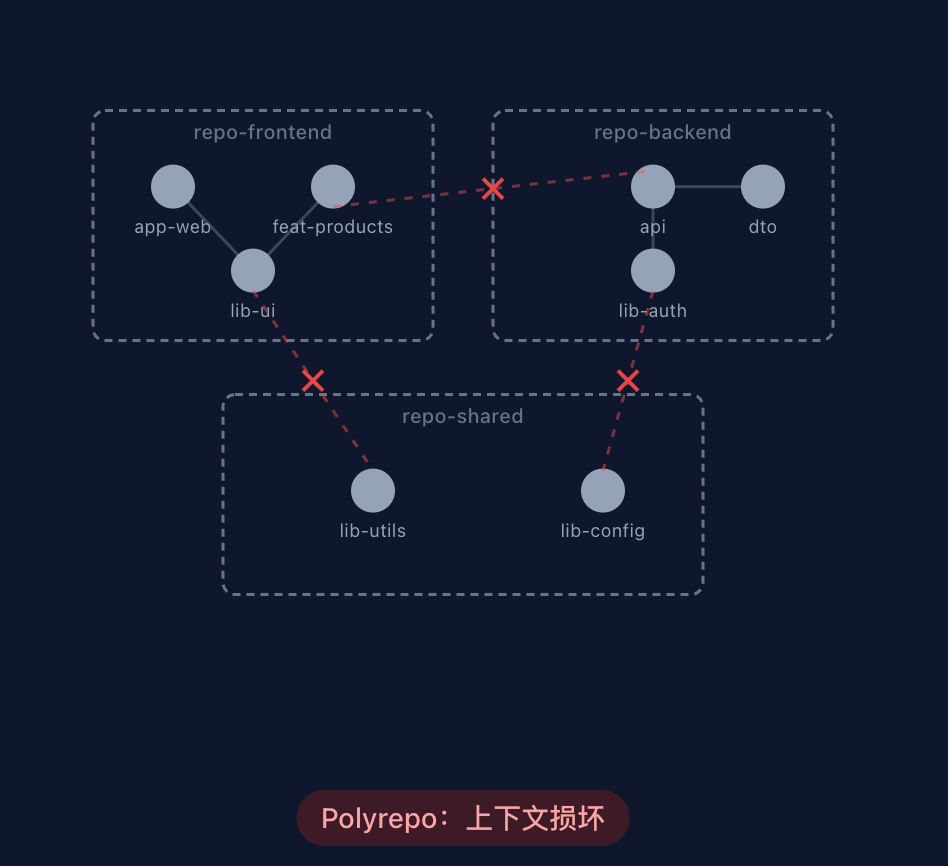
对于传统的需求,基本上无法实现一个仓库完成全部需求工作,而对于 Agent 而言,跨多仓库的任务会存在以下问题:
- 频繁切换仓库
- 不同仓库提供的工具链有差异
- 多个 MR 拆分
Monorepo 最核心的 AI 友好特性是所有代码共享一个仓库,使得 Agent 在处理原本跨服务链路时无需跨仓库跳转且依赖关系可见,也不存在发布依赖的风险。同时对于大型单体仓库的上下文问题,前文的服务/模块地图、多级知识库就可以较好地解决。
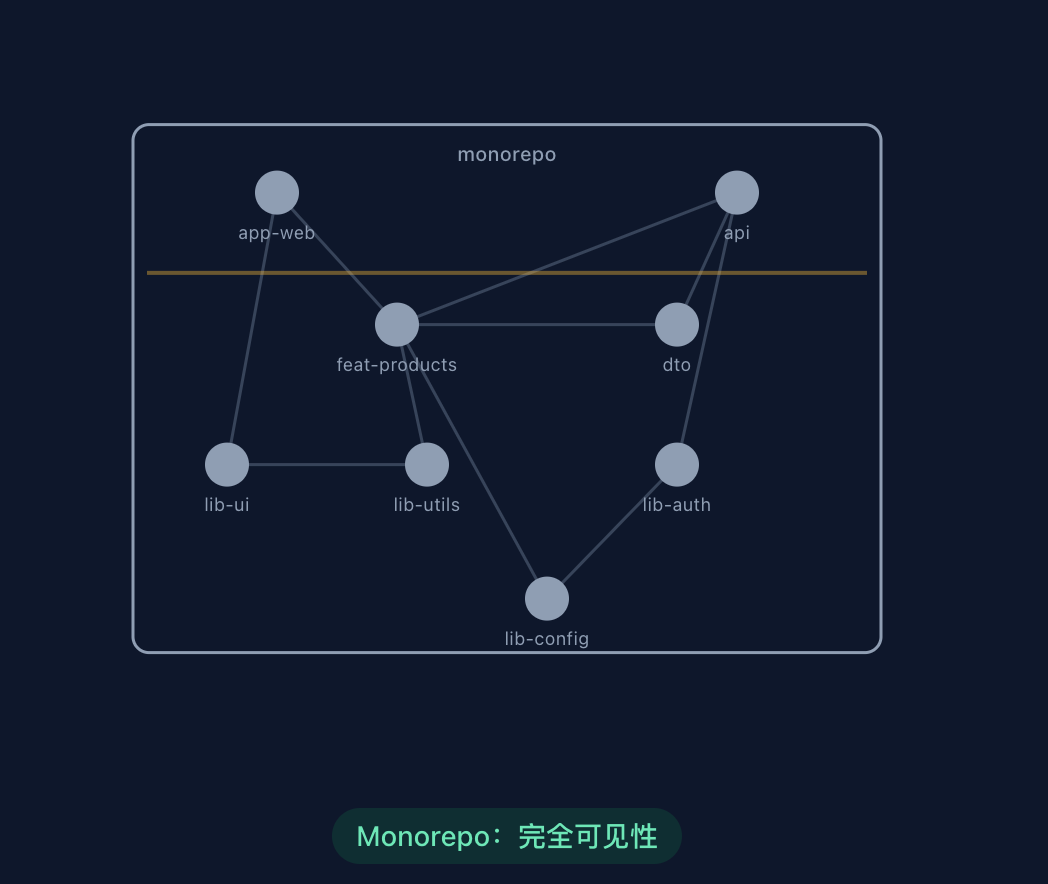
但 Monorepo 引入后,AI Agent 生成代码时常犯的架构错误就是跨模块随意引用内部的实现,而 golang 的 internal/ 目录天然提供了编译器级别的边界设定:其目录下的代码只能被其父目录树中的代码导入。
legacy/
├── internal/ # 编译器禁止外部 import
│ ├── article/
│ ├── short_video/
│ └── shared/ 除了 internal,golangci-lint 以及后置的一些 CI 流程也可以对生成代码进行运行前的检测。
# .golangci.yml 中的 depguard 配合 internal
linters-settings:
depguard:
rules:
domain:
deny:
- pkg: "feature"
desc: "domain 层禁止直接依赖 feature"第三层:测试类架构
测试类架构为 AI 的代码生成和修改提供质量保障,也为 Agent 在执行过程中提供回调自检的能力。
Agent 一分钟生成了 500 行代码,但人工 review 要花 20 分钟。
当 Agent 能快速产出大量代码时,人工 review 本身就成了最大瓶颈。Veracode 2025 年的研究跑了 80 项编码任务、使用 100 多个 LLM,结果有 45% 的代码生成任务引入了安全漏洞。
质检机制:用自动化质检解放人力
传统质检已经跟不上 Agent 的代码生成速度,必须把自动化检查前置,分担 review 压力。业内目前在用的各类质检卡点:
| 流程 | 质检卡点 |
|---|---|
| 常态 | - Spec 与知识库 diff |
| Agent 任务前置 | - 权限检查 - 核心文件保护 |
| 任务执行过程 | - 依赖关系分析 - 编译检查 - linter - 黑盒测试 - 门禁脚本 - Prompt / 子 Agent 验证 |
| 任务完成前 | - 黑盒测试 |
| 任务完成后 | - 单元 + 属性测试 - 影响分析 - CI 流水线 - 性能分析 |
| 任务提交后 | - 发车、线上回归 |
质检的内容对于 Agent 任务来说很重要,如果随上下文被压缩,则会导致模型无法修复已知问题,可以通过质检本地化(比如随 Spec 流程存放)解决
自动化测试过程随业务变更,同时可以在过程中自动收集度量指标:
- 门禁拦截率:各个阶段的拦截率
- 质检耗时:各个阶段的质检执行耗时(prompt 类型质检越久越消耗 token)
- AI 变更异常率:AI 对仓库变更的熟悉程度
- 目录异常率:记录目录异常率并排序,质检优先执行
面向打包这类频繁变更的场景,Bazel 接入后 flaky test (大概率也是 AI 生成),可以在自动化质检中标记,所有质检都为业务服务
测试左移:把测试从上线前提前到开发中
测试左移不是简单地”早点写测试”,而是用更强的测试形式对抗更快的代码生成速度。
- TDD:
传统的 TDD(Test-Driven Development)是先写一个失败的 test,然后修改最少的代码使其 pass
AI 时代的 TDD 即让 AI 先写测试,再写实现,也可在 AGENTS.md/ 或者 Rules 中制定并开启 TDD 工作流
| 问题 | 无 TDD | 有 TDD |
|---|---|---|
| 目标模糊 | AI 自行脑补函数签名、返回值、边界处理 | 测试 case 已经定义了输入到结果要求,AI 只需满足约束 |
| 过度设计 | AI 可能搞出 3 层抽象 + 2 个 interface | 测试只关心行为,AI 会写出刚好够用的最简实现 |
| 隐式偏移 | 改了函数 A,但破坏了函数 B | 已有测试立刻报红,AI 在同一轮修复 |
| 验证依赖人 | “代码看起来对”,但没测试过 | AI 自己跑测试,PASS 了才输出 |
对于 TDD 反模式下的单测一般存在如下问题:
现有单测生成痛点:
| 反模式 | 表现 | 如何防御 |
|---|---|---|
| 先实现后补测试 | AI 写了 200 行代码,最后补测试 | Rules 中明确禁止,要求先看到 FAIL 再写实现 |
| 恒真测试 | assert.True(t, true) 或只检查 err == nil | Checklist 要求注释掉实现后测试必须 FAIL |
| 测试抄实现 | 测试里复制了一遍业务逻辑来对比 | Rules 中要求测试用硬编码期望值,不可调用被测函数的内部逻辑 |
| 过度 Mock | 每个依赖都 Mock,测试只验证了 Mock 的行为 | Rules 中明确区分哪些依赖可以 Mock |
- PBT(Property-Based Testing):
传统测试是写几个 case 覆盖已知场景,但 AI 生成代码的问题恰恰在未知场景:AI 可以让所有你写的 test case 通过,但对未覆盖的场景里的异常则难以捕获。PBT 换一个角度——不关心”输入 A 得到输出 B”,而是关心”对任意合法输入,某个属性必须成立”。属性可以理解为一组输入与行为上的不变量。
Kiro 在 Agent 工作流中将 PBT(Property-Based Testing) 融合到了 Spec(使用 Hypothesis):
- Spec 阶段:做一个小型交通信号灯模拟器,任何两个方向的车辆都不能同时为绿灯(自然语言 + 类型签名描述业务规则)
- Property 阶段:Agent 将业务规则翻译为可执行的数学属性
- 实现阶段:AI 生成代码后,执行 PBT test
- 回归阶段:每次修改, PBT 以海量随机输入重新验证
Anthropic 也探索了相同的方向:Spec → PBT 结合自动化验证。
影响预测:质检减负
AI 生成的 MR 根据需求,如果通常修改量大、涉及文件多。传统 CI 要么跑全量测试,要么人工 review 判断影响范围。影响预测的核心是:在 MR 合并前,自动分析这次变更会影响哪些模块,只跑必要的测试,同时备注高风险模块。
同时 AI 在 Spec 等执行过程中,操作的影响范围如果无法预估,则在 实际的 TDD 流程中也会影响 Test 生成的准确率。因此 影响预测 可以作为 脚本、单测文件等方式提供,自动化地根据业务模块间依赖进行分析,反馈给 Agent。
golang 天然支持依赖分析 go list ,以零成本构建影响预测
- AI 生成的变更影响范围图计算逻辑:
// tools/impactanalysis/main.go
// 读取 git diff 文件列表,通过 go 依赖图计算影响范围,输出需要测试的 package 列表
package main
import (
"encoding/json"
"fmt"
"os"
"os/exec"
"path/filepath"
"strings"
)
type ImpactReport struct {
ChangedPackages []string `json:"changed_packages"`
AffectedPackages []string `json:"affected_packages"`
RiskLevel string `json:"risk_level"` // low / medium / high / critical
TestCommand string `json:"test_command"`
}
func main() {
// Step 1: 获取本次变更的文件列表
changedFiles := getChangedFiles()
// Step 2: 映射到 Go packages
changedPkgs := filesToPackages(changedFiles)
// Step 3: 通过 go list 反向依赖图,找出所有受影响的 package
affectedPkgs := findAffectedPackages(changedPkgs)
// Step 4: 计算风险等级
risk := assessRisk(changedPkgs, affectedPkgs)
// Step 5: 生成精准测试命令
report := ImpactReport{
ChangedPackages: changedPkgs,
AffectedPackages: affectedPkgs,
RiskLevel: risk,
TestCommand: buildTestCommand(affectedPkgs),
}
json.NewEncoder(os.Stdout).Encode(report)
// CI 门禁:high/critical 风险需要额外审批
if risk == "critical" {
fmt.Fprintln(os.Stderr, "CRITICAL: blast radius > 30% of modules, requires senior review")
os.Exit(1)
}
}
func getChangedFiles() []string {
out, err := exec.Command("git", "diff", "--name-only", "origin/main...HEAD").Output()
if err != nil {
panic(err)
}
var files []string
for _, f := range strings.Split(strings.TrimSpace(string(out)), "\n") {
if strings.HasSuffix(f, ".go") {
files = append(files, f)
}
}
return files
}
func filesToPackages(files []string) []string {
pkgSet := map[string]bool{}
for _, f := range files {
pkgSet[filepath.Dir(f)] = true
}
var pkgs []string
for p := range pkgSet {
pkgs = append(pkgs, "./"+p)
}
return pkgs
}
func findAffectedPackages(changedPkgs []string) []string {
// go list -f '{{.ImportPath}}' -deps -test ./... 获取完整依赖图
// 然后反向查找:谁 import 了 changedPkgs 中的包
affected := map[string]bool{}
for _, pkg := range changedPkgs {
affected[pkg] = true
// go list -f '{{join .Deps "\n"}}' 的反向查询
out, err := exec.Command("go", "list", "-f",
fmt.Sprintf(`{{if (contains .Deps "%s")}}{{.ImportPath}}{{end}}`, pkg),
"./...").Output()
if err != nil {
continue
}
for _, line := range strings.Split(string(out), "\n") {
line = strings.TrimSpace(line)
if line != "" {
affected[line] = true
}
}
}
var result []string
for p := range affected {
result = append(result, p)
}
return result
}
func assessRisk(changed, affected []string) string {
// 获取项目总 package 数
out, _ := exec.Command("go", "list", "./...").Output()
total := len(strings.Split(strings.TrimSpace(string(out)), "\n"))
ratio := float64(len(affected)) / float64(total)
switch {
case ratio > 0.3:
return "critical" // >30% 模块受影响
case ratio > 0.15:
return "high"
case ratio > 0.05:
return "medium"
default:
return "low"
}
}
func buildTestCommand(pkgs []string) string {
if len(pkgs) == 0 {
return "echo 'no packages affected'"
}
return fmt.Sprintf("go test -count=1 -race %s", strings.Join(pkgs, " "))
}影响分析的核心指标:
- 平均爆炸半径
- 测试时间优化率
相关链接
- https://bytetech.info/articles/7616269166214905906?from=message_bot&sender_type=101&message_id=7619152933578588211&column=like#Fk7ydcpiUoWy20xN2V3cYQFinQd
- 构建 AI Agent 友好型代码仓库 | Create Agent-Friendly Repository
- AI 友好度评价体系规范 v0.2
- https://openai.com/zh-Hans-CN/index/harness-engineering/
- github.blog — Quantifying Copilot’s Impact with Accenture
- jimmybogard.com/vertical-slice-architecture
- code.claude.com/docs/en/best-practices
- https://bytetech.info/articles/7618118681893502985?from=message_bot&sender_type=101&message_id=7619152933578588211&column=like#doxlgPESBKG2dbLIFvhlPbjcZvh
- https://developers.openai.com/blog/skills-agents-sdk#keep-workflows-in-the-repo
- https://www.propelcode.ai/blog/structuring-codebases-for-ai-tools-2025-guide